《代码块读取 EXCEL 文件内容》这篇文章我们实现了代码块读取 Excel,但是在实际的业务数据处理工作中,我们经常需要处理大型 Excel 文件,我们发现当处理大型 Excel 文件(特别是包含数万行数据时)会遇到两个关键问题:
- 内存溢出风险:直接全量读取可能导致内存不足
- 执行超时:单次处理大数据量易触发代码块执行超时限制
本文将分享一个经过实战检验的 Python 分块处理方案,可稳定处理 GB 级 Excel 文件。
解决方案架构:
- 内存中处理:通过
<span class="color_font"><strong><span>BytesIO</span></strong></span>将下载的 Excel 文件保存在内存中,避免频繁磁盘 IO - 设置分块:将大数据集分割成多个小块处理,每块默认 200 行(可自定义)
- 异常处理:对每个工作表单独处理,避免一个表出错影响整体
- 指针重置:每次读取后重置文件指针,确保后续读取正常
- 读取分块:接收行号区域,进行内容提取
预处理:Excel 分页代码
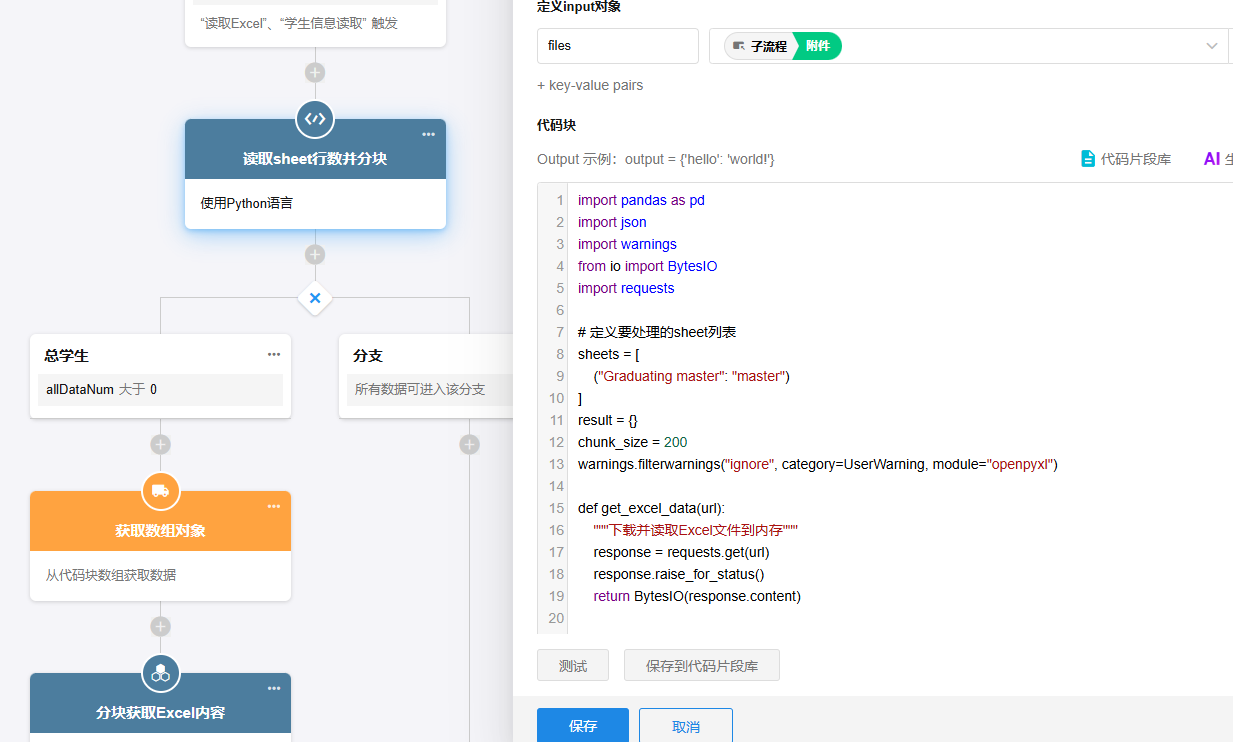
#私有模式下支持 安装pandas与openpyxl库
import pandas as pd
import json
import warnings
from io import BytesIO
import requests
# 定义要处理的sheet列表(实际sheet名,输出别名)
sheets = [
("Graduating master", "master")
]
result = {}
#分块大小
chunk_size = 200
warnings.filterwarnings("ignore", category=UserWarning, module="openpyxl")
def get_excel_data(url):
"""下载并读取Excel文件到内存"""
response = requests.get(url)
response.raise_for_status()
return BytesIO(response.content)
def process_sheet(excel_data, sheet_name, chunk_size):
"""处理单个sheet"""
try:
df = pd.read_excel(excel_data, sheet_name=sheet_name, engine='openpyxl')
total_rows = len(df)
num_chunks = (total_rows + chunk_size - 1) // chunk_size
chunks = []
for i in range(num_chunks):
start = i * chunk_size
end = min(start + chunk_size - 1, total_rows - 1)
chunks.append({"bind": start, "eind": end})
return {
"count": len(chunks),
"data": chunks,
"total_rows":total_rows
}
except Exception as e:
print(f"处理工作表 {sheet_name} 时出错: {str(e)}")
return {"count": 0, "data": []}
url = json.loads(input['files'])[0]
excel_data = get_excel_data(url)
for sheet_name, output_key in sheets:
excel_data.seek(0)
processed = process_sheet(excel_data, sheet_name, chunk_size)
result[f"{output_key}Num"] = processed["count"]
result[f"{output_key}total"] = processed["total_rows"]
result[output_key] = processed["data"]
output = result
判断 total 是否大于 0;使用获取批量数据节点;获取分块数组;然后调用子流程--【分块读取内容】
分块读取内容
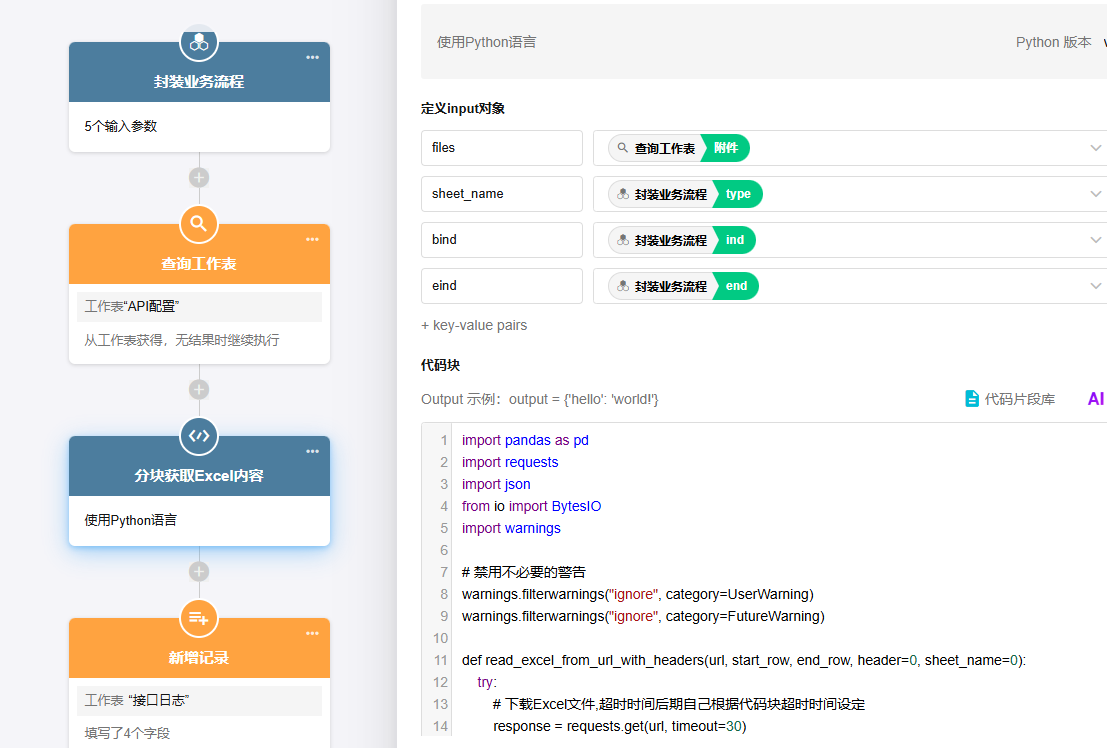
import pandas as pd
import requests
import json
from io import BytesIO
import warnings
# 禁用不必要的警告
warnings.filterwarnings("ignore", category=UserWarning)
warnings.filterwarnings("ignore", category=FutureWarning)
def read_excel_from_url_with_headers(url, start_row, end_row, header=0, sheet_name=0):
try:
# 下载Excel文件,超时时间后期自己根据代码块超时时间设定
response = requests.get(url, timeout=30)
response.raise_for_status()
excel_data = BytesIO(response.content)
full_df = pd.read_excel(
excel_data,
header=header,
sheet_name=sheet_name,
engine='openpyxl'
)
if full_df.empty:
print("警告: 读取的DataFrame为空")
return None
if start_row < 0 or end_row >= len(full_df):
print(f"错误: 行号超出范围 (数据总行数: {len(full_df)})")
return None
selected_df = full_df.iloc[start_row:end_row+1].copy()
str_df = selected_df.astype(str)
return str_df
except requests.exceptions.RequestException as e:
print(f"下载文件失败: {e}")
return None
except pd.errors.EmptyDataError:
print("错误: Excel文件为空或格式不正确")
return None
except Exception as e:
print(f"处理文件时出错: {str(e)}")
return None
try:
input_data = json.loads(input['files'])[0]
excel_url =input_data
start_row = int(input['bindex'])
end_row = int(input['eindex'])
sheet_name = input.get('sheetname', 0) # 默认为第一个sheet
df = read_excel_from_url_with_headers(excel_url, start_row, end_row, 0, sheet_name)
if df is not None:
json_data = json.dumps(df.to_dict(orient='records'), ensure_ascii=False)
output = {'result': json_data}
else:
output = {'error': '无法读取Excel数据', 'details': '请检查URL和参数是否正确'}
except json.JSONDecodeError:
output = {'error': '输入参数JSON解析失败'}
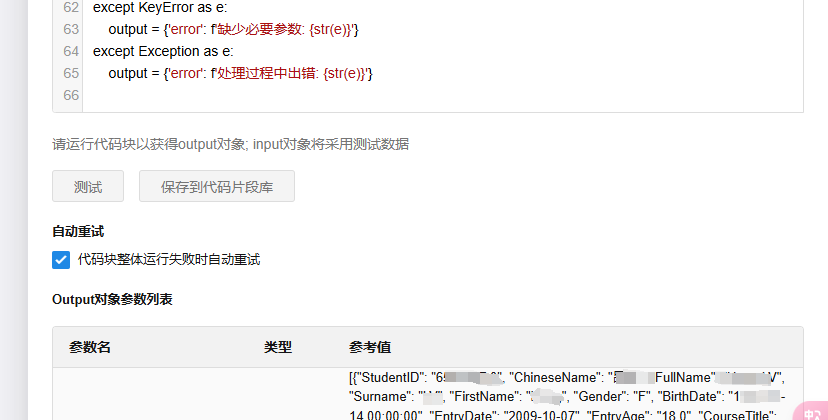
except KeyError as e:
output = {'error': f'缺少必要参数: {str(e)}'}
except Exception as e:
output = {'error': f'处理过程中出错: {str(e)}'}
通过这种分块处理机制,我们成功将原先无法处理的大型 Excel 文件任务分解为可管理的小任务。代码块输出的数据如何使用,自行根据业务进行处理即可。实际测试中,该方案已稳定处理过单文件超过 50 万行数据的业务场景。
后续操作建议:
1。根据据业务需求调整 chunk_size
2。根据代码块超时时间,自行设置读取 Excel 的超时时间
3。如果某些列需要进行特殊处理,添加对应的逻辑处理






