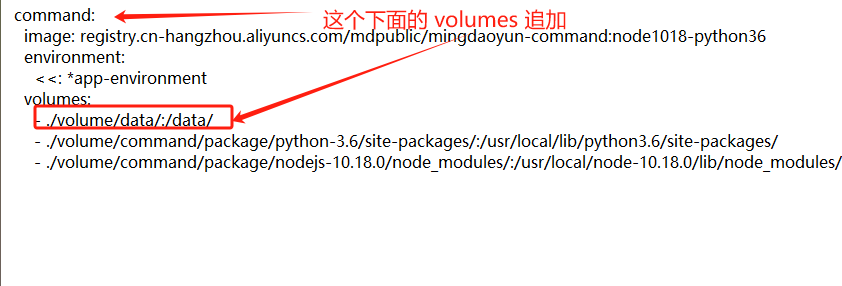
这个主题,之前帖子已回复过实现方式,但是还是客户咨询配置方式。今天落实到单贴,详细步骤如下:
- 私有环境依赖库持久化 https://docs.pd.mingdao.com/faq/codeextension
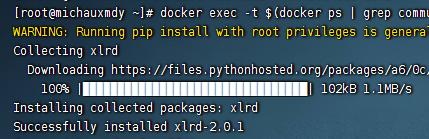
- 解析 Excel 的类库,xlrd/openpyx :
docker exec -t $(docker ps | grep community | awk '{print $1}') bash -c 'pip3 install --target=/usr/local/lib/python3.6/site-packages/ xlrd'
新版本 2.0.1 不支持解析 xlsx,所以需要指定版本 xlrd==1.2.0
![image.png]()
- 流程内代码块配置:
![image.png]()
![image.png]()

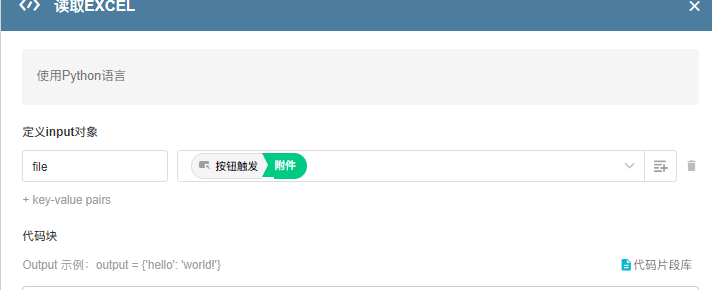
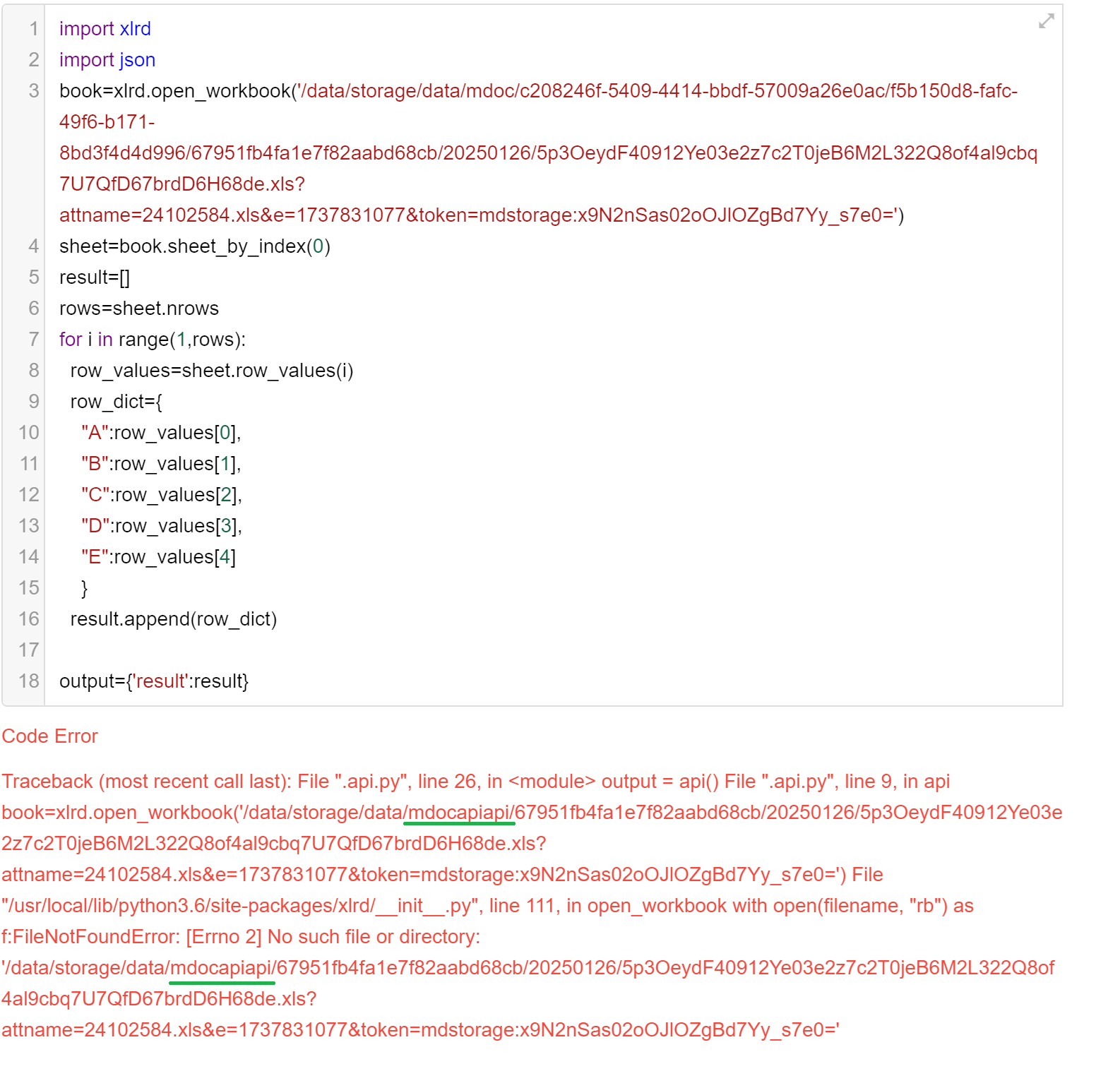
import xlrd
import json
file_addr=input['file']
import xlrd
import json
file_addr=input["file"]
file_http_path=file_addr[2:len(file_addr)-2]
file_path_list=file_http_path.split('?')[0]
file_path='/data/storage/data/'+file_path_list.replace('http://192.168.81.128:8880/file/','')
#http://192.168.81.128:8880 请替换为你的访问地址
book=xlrd.open_workbook(file_path)
sheet=book.sheet_by_index(0)
result=[]
rows=sheet.nrows
for i in range(1,rows):
row_values=sheet.row_values(i)
row_dict={
"A":row_values[0],
"B":row_values[1],
"C":row_values[2],
"D":row_values[3],
"E":row_values[4]
}
result.append(row_dict)
output={'路径':file_path,'结果':result}
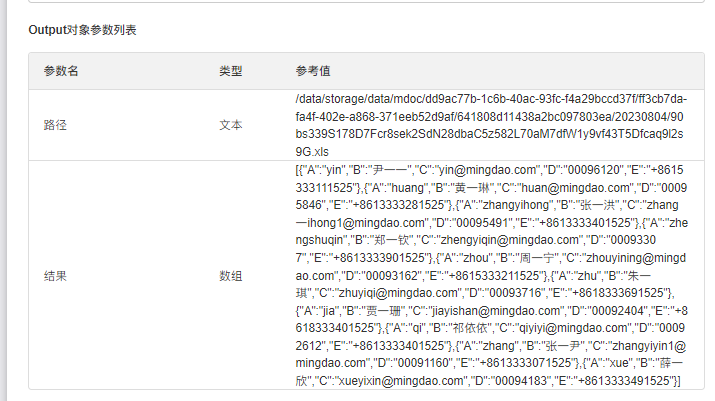
代码块返回的数组(可对于数据过滤后再输出),通过【获取批量数据】+【子流程/封装业务流】节点进行处理;如果数据量大,也可以在代码块内调用【工作表 API 接口】对于数据进行增删改。
-------以上只适用于单机版,文件存储集群模式下,将文件分片分散存储在多个独立的节点上;------
以下方案都适用
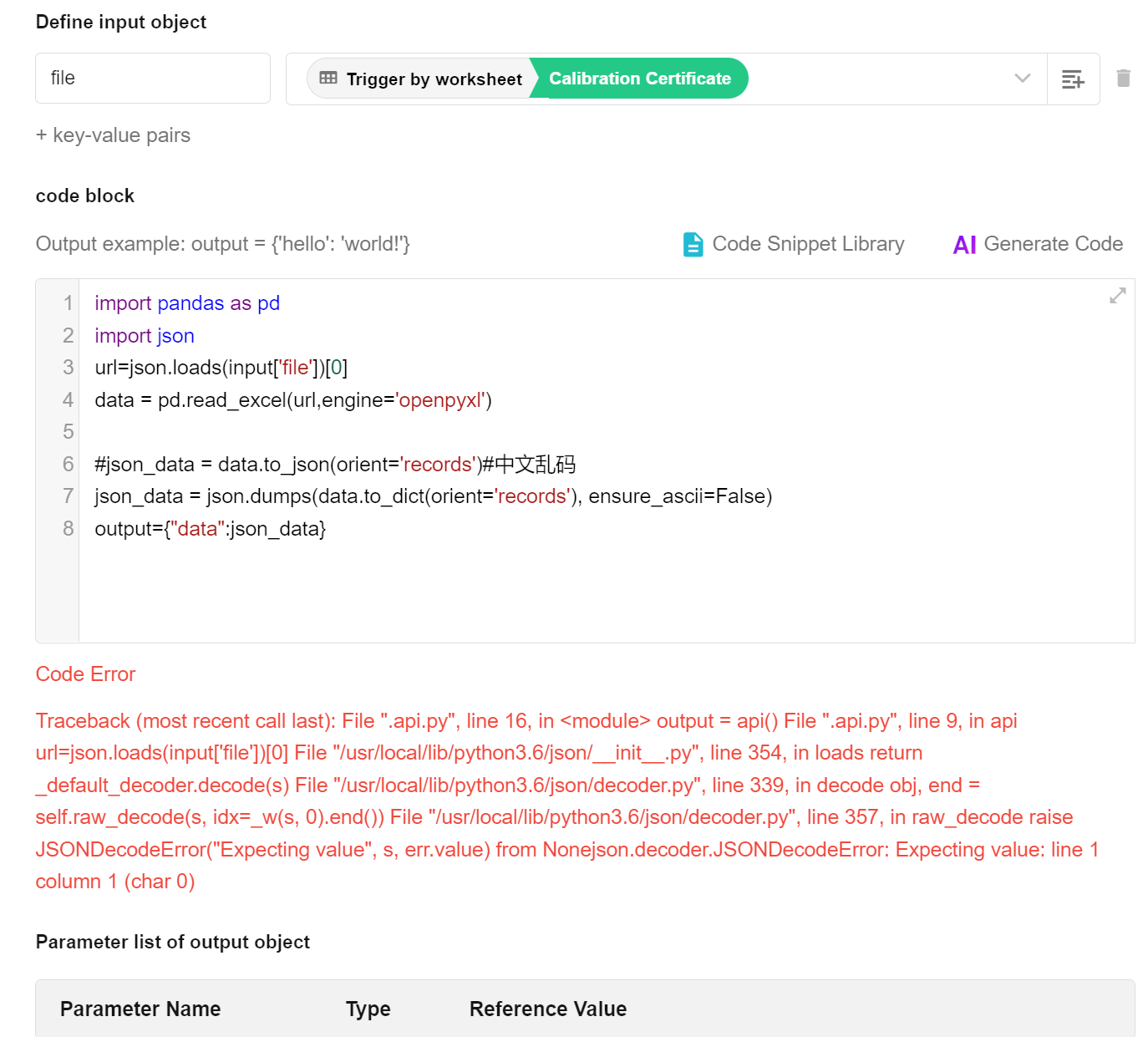
- 安装 python 的
pandas库 - 按下列流程配置
![image.png]()
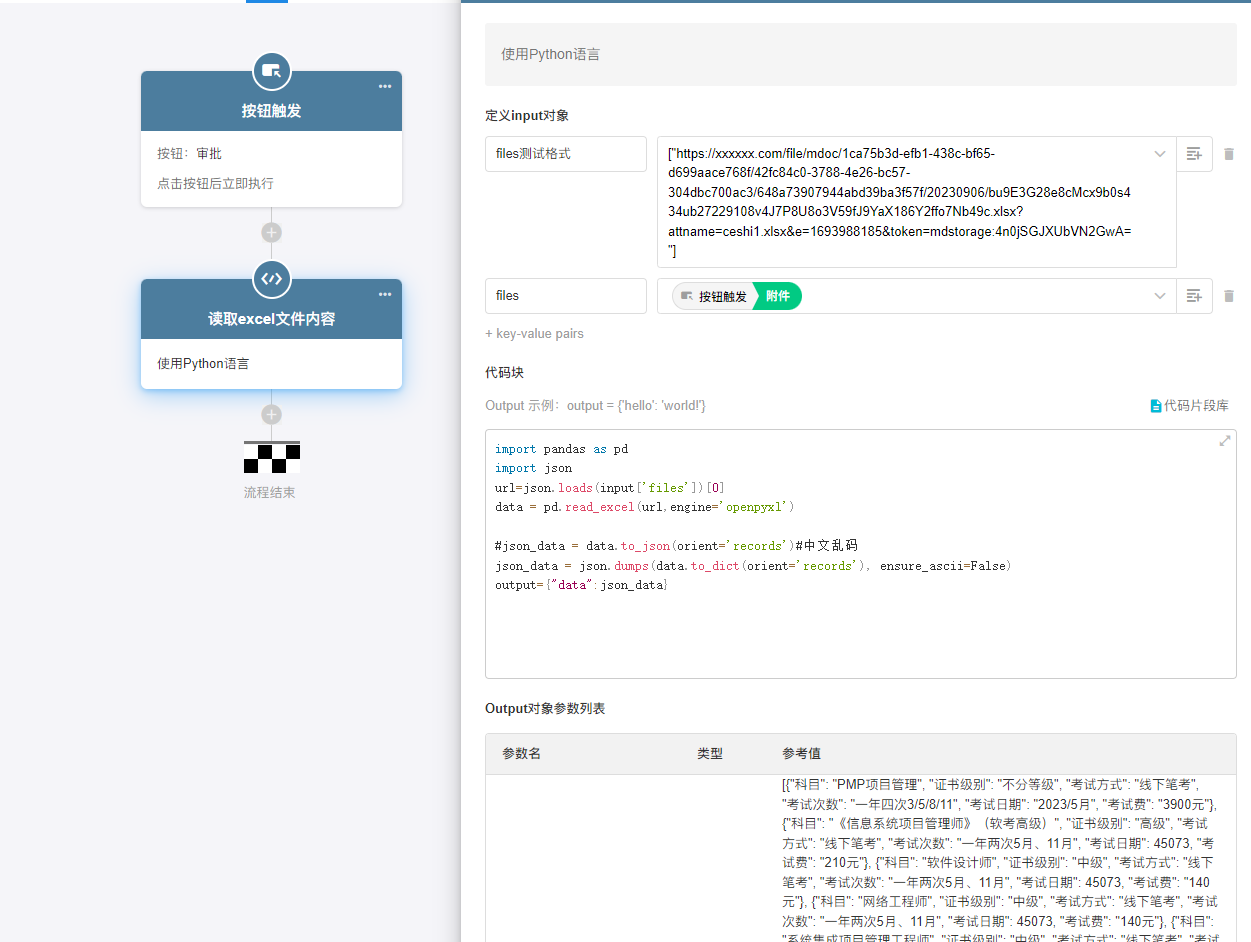
import pandas as pd
import json
url=json.loads(input['files'])[0]
data = pd.read_excel(url,engine='openpyxl')
#json_data = data.to_json(orient='records')#中文乱码
json_data = json.dumps(data.to_dict(orient='records'), ensure_ascii=False)
output={"data":json_data}