如果我想实现将 A 表数据存储到 B 表中 需要实现过滤的是除附件外重复数据做清洗
如下
记录 1:
字段 A 字段 B 字段 C 附件 A
记录 2:
字段 A 字段 B 字段 C 附件 B
记录 3:
字段 A 字段 B 字段 C 附件 C
如果 ABC 一致实现过滤保留任意一条记录即可(附件不保留)

如果我想实现将 A 表数据存储到 B 表中 需要实现过滤的是除附件外重复数据做清洗
如下
记录 1:
字段 A 字段 B 字段 C 附件 A
记录 2:
字段 A 字段 B 字段 C 附件 B
记录 3:
字段 A 字段 B 字段 C 附件 C
如果 ABC 一致实现过滤保留任意一条记录即可(附件不保留)
有1人点赞 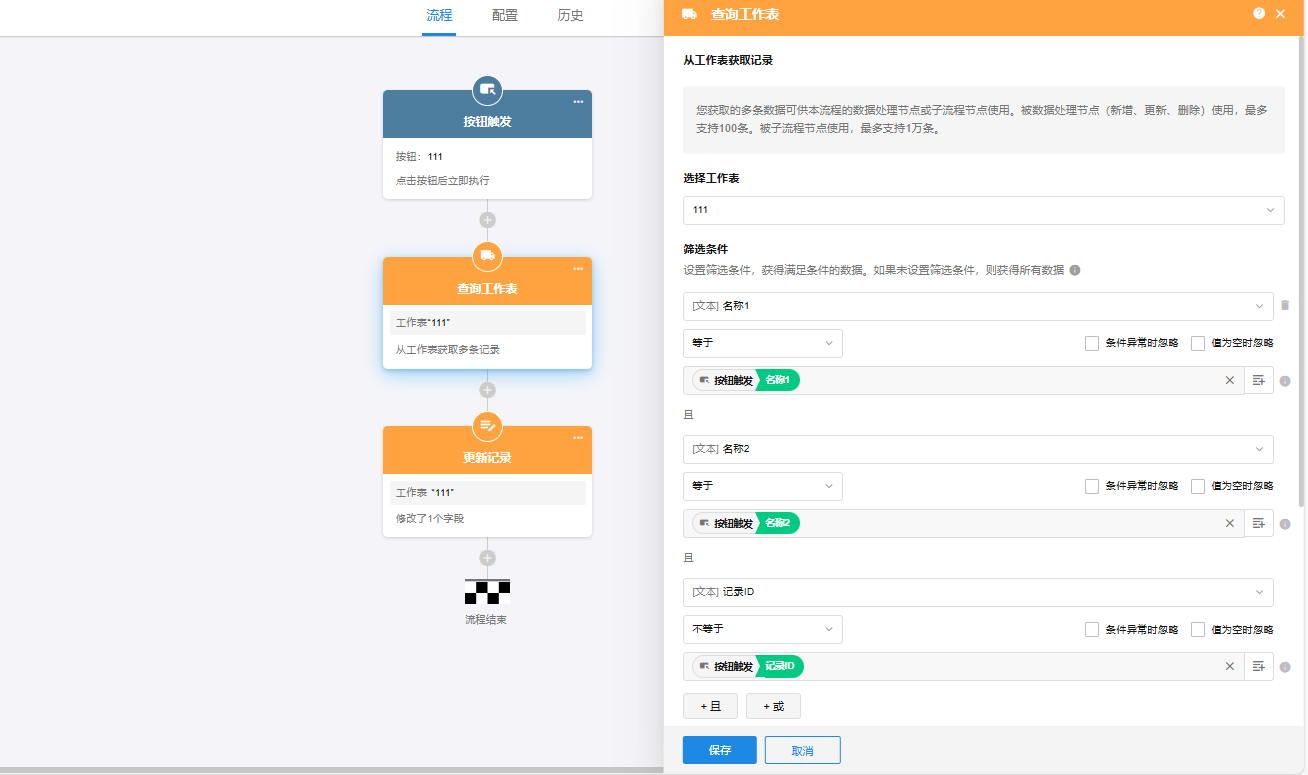
无法理解哪里出问题了
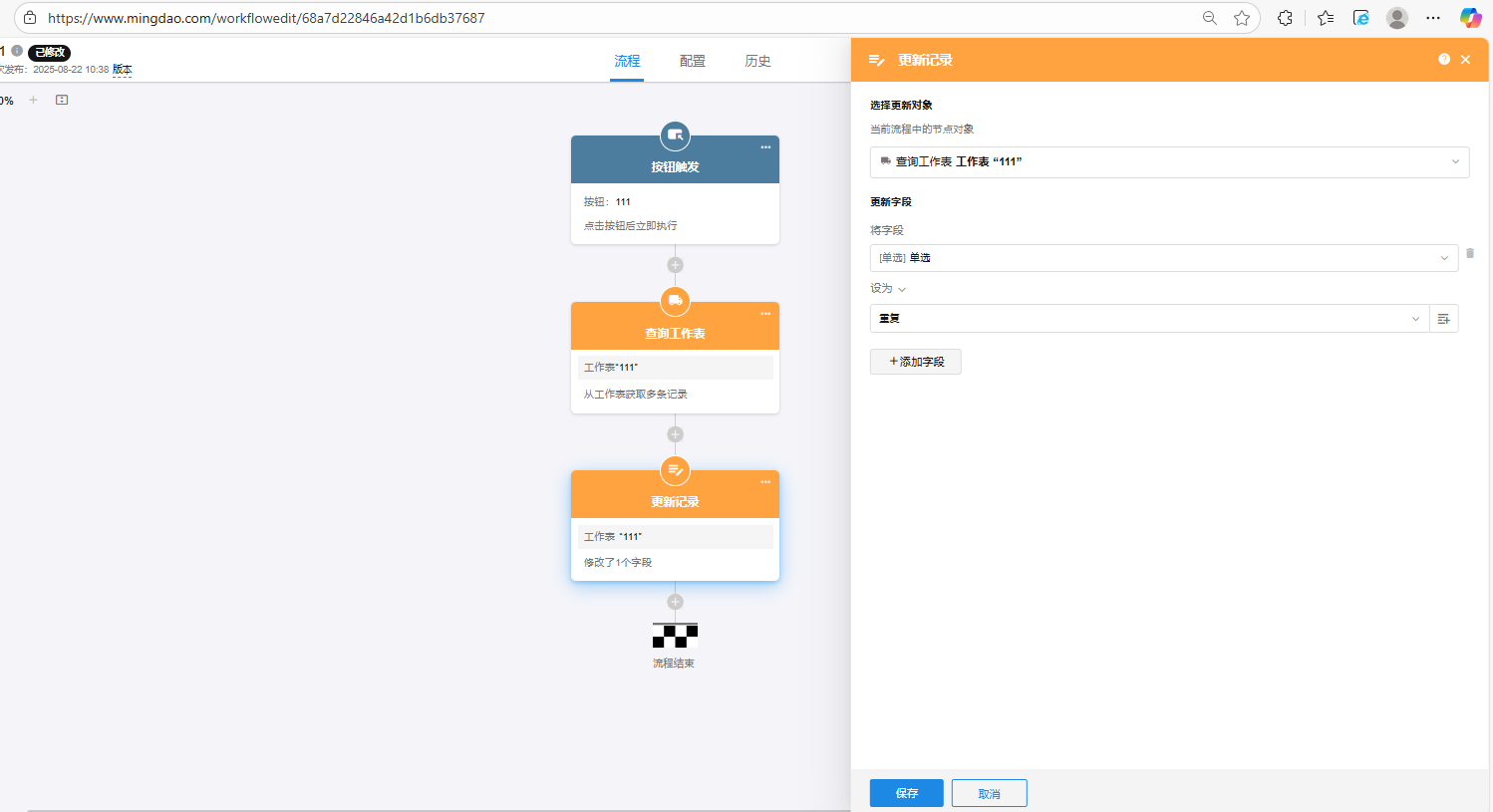
不是,设置别名之后,代码块就可以根据你的别名去访问字段,像我刚刚实例代码里面 a b 就是别名
大佬,我想弄明白 按楼下哥们说的 再加一个单选字段是否已筛选重复。用定时工作流或者按钮筛选所有数据,每条数据去找工作表中 ABC 字段都相同且 ID 不等于本条记录 ID 的,有就新单项字段标记已筛选重复,获取重复数据标记已筛选重复;没有就标记已筛选并写入 B 表 每条数据去找工作表中 ABC 字段都相同且 ID 不等于本条记录 ID 的(这一部怎么添加)

这个实现的是表内对比吗?
不是,设置别名之后,代码块就可以根据你的别名去访问字段,像我刚刚实例代码里面 a b 就是别名
可以在工作表字段名称设置字段别名
这个实现的是表内对比吗?
import json # 解析 records 字符串为对象数组 def parse_records(s): try: return json.loads(s) except: return [] # 解析 keys 字符串为字段名列表 def parse_keys(s): try: keys = json.loads(s) if isinstance(keys, list): return list(dict.fromkeys(str(k).strip() for k in keys if k)) # 去重保持顺序 except: pass return [] records_raw = input.get("records", "") keys_raw = input.get("keys", "") records = parse_records(records_raw) keys = parse_keys(keys_raw) if not keys: output = { "错误": "字段名数组为空或格式错误,应为字符串格式,如 '[\"a\", \"b\"]'", "使用的字段": [], "保留记录": [], "去除记录数": 0, "显示列表": [] } else: seen = set() unique = [] preview = [] for r in records: combo = tuple(str(r.get(k, "")).strip() for k in keys) if combo not in seen: seen.add(combo) # 只保留指定字段 filtered = {k: r.get(k, "") for k in keys} unique.append(filtered) # 构造可读预览 text = "记录 {}:".format(len(unique)) + " ".join(f"{k}={filtered[k]}" for k in keys) preview.append(text) output = { "保留记录": unique, "去除记录数": len(records) - len(unique), "使用的字段": keys, "显示列表": preview }
根据字段名组合 keys 去重
可以在工作表字段名称设置字段别名
import json
# 解析 records 字符串为对象数组
def parse_records(s):
try:
return json.loads(s)
except:
return []
# 解析 keys 字符串为字段名列表
def parse_keys(s):
try:
keys = json.loads(s)
if isinstance(keys, list):
return list(dict.fromkeys(str(k).strip() for k in keys if k)) # 去重保持顺序
except:
pass
return []
records_raw = input.get("records", "")
keys_raw = input.get("keys", "")
records = parse_records(records_raw)
keys = parse_keys(keys_raw)
if not keys:
output = {
"错误": "字段名数组为空或格式错误,应为字符串格式,如 '[\"a\", \"b\"]'",
"使用的字段": [],
"保留记录": [],
"去除记录数": 0,
"显示列表": []
}
else:
seen = set()
unique = []
preview = []
for r in records:
combo = tuple(str(r.get(k, "")).strip() for k in keys)
if combo not in seen:
seen.add(combo)
# 只保留指定字段
filtered = {k: r.get(k, "") for k in keys}
unique.append(filtered)
# 构造可读预览
text = "记录 {}:".format(len(unique)) + " ".join(f"{k}={filtered[k]}" for k in keys)
preview.append(text)
output = {
"保留记录": unique,
"去除记录数": len(records) - len(unique),
"使用的字段": keys,
"显示列表": preview
}
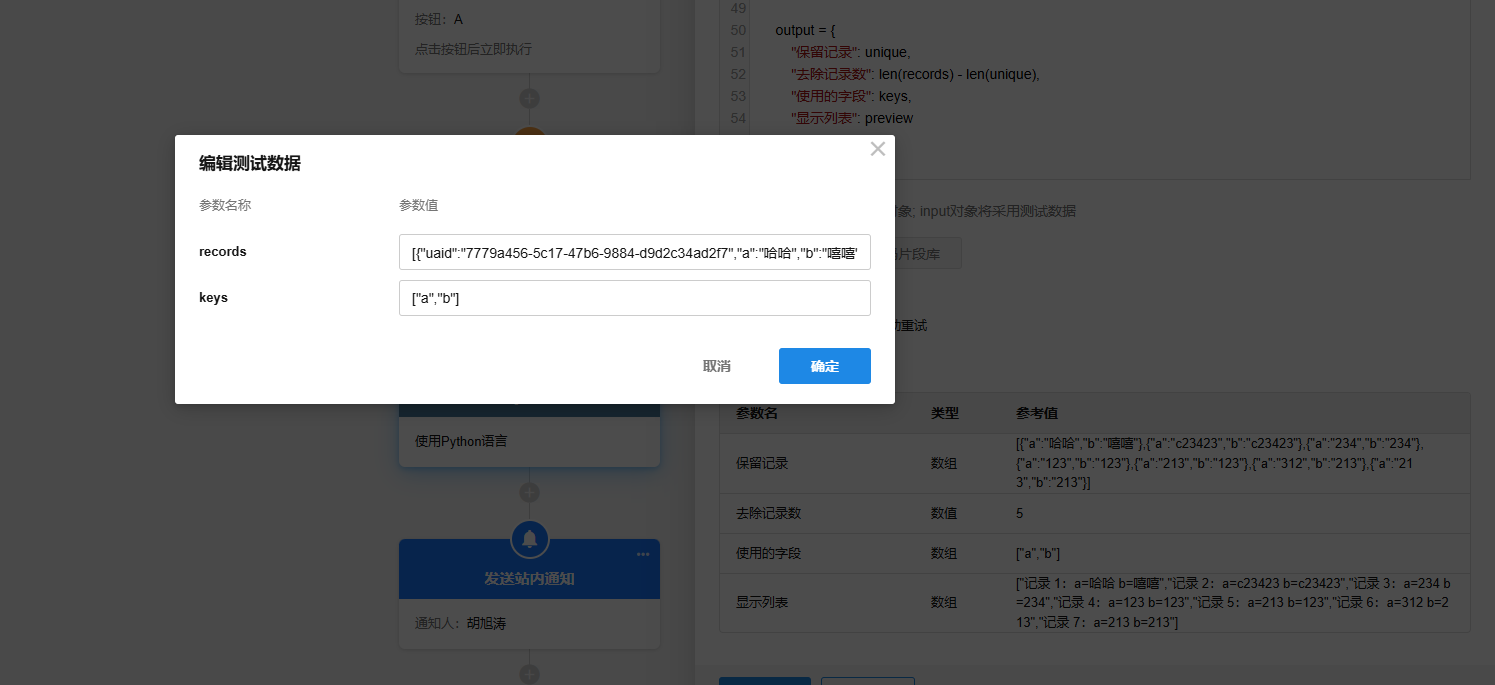
根据字段名组合 keys 去重
- 再加一个单选字段是否已筛选重复。用定时工作流或者按钮筛选所有数据,每条数据去找工作表中 ABC 字段都相同且 ID 不等于本条记录 ID 的,有就新单项字段标记已筛选重复,获取重复数据标记已筛选重复;没有就标记已筛选并写入 B 表
2、 或者用代码块,论坛里面有方法的:https://bbs.mingdao.net/topic/6353
3、A 表全部数据导出为 Excel,合并 ABC 字段。然后用 Excel 去除重复项或者标记重复项。增加标记重复的字段,重新导入 A 表标记,或者直接导入 B 表
如果是每天都要执行这个环节,可以用工作流。如果是一次性工作,导出表格最快,不消耗工作流
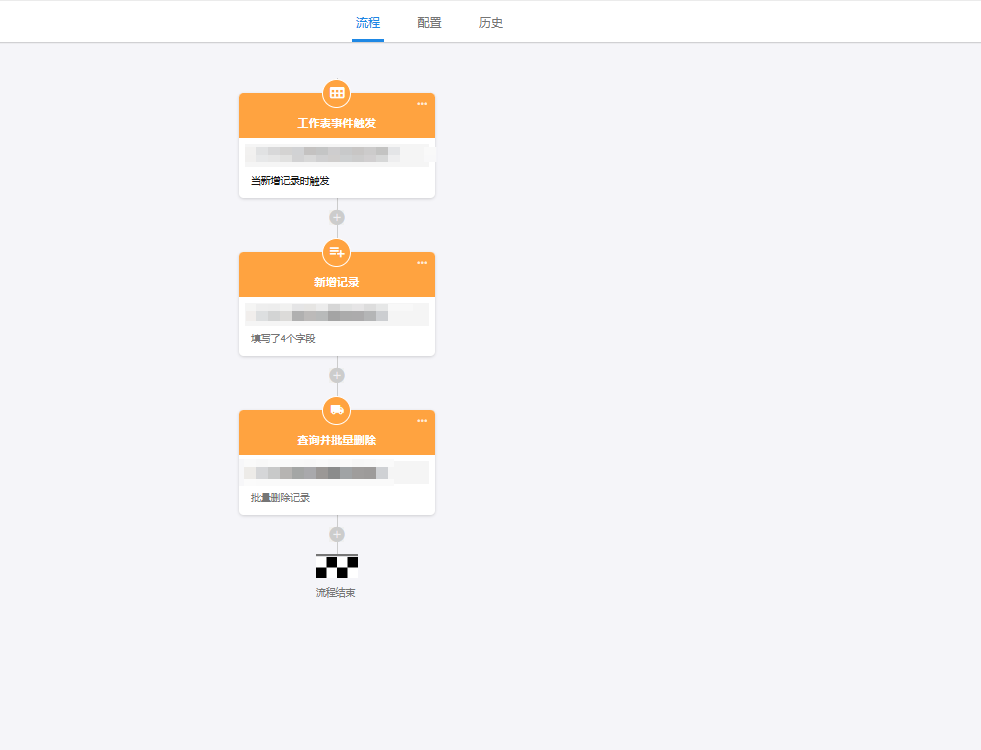 这是我实现的工作流 为什么无法获取到数据望指教
这是我实现的工作流 为什么无法获取到数据望指教
添加“Same Record Amount”字段,用工作流算好填进去,即可。
Same Record Amount 在哪?
- 再加一个单选字段是否已筛选重复。用定时工作流或者按钮筛选所有数据,每条数据去找工作表中 ABC 字段都相同且 ID 不等于本条记录 ID 的,有就新单项字段标记已筛选重复,获取重复数据标记已筛选重复;没有就标记已筛选并写入 B 表
2、 或者用代码块,论坛里面有方法的:https://bbs.mingdao.net/topic/6353
3、A 表全部数据导出为 Excel,合并 ABC 字段。然后用 Excel 去除重复项或者标记重复项。增加标记重复的字段,重新导入 A 表标记,或者直接导入 B 表
如果是每天都要执行这个环节,可以用工作流。如果是一次性工作,导出表格最快,不消耗工作流
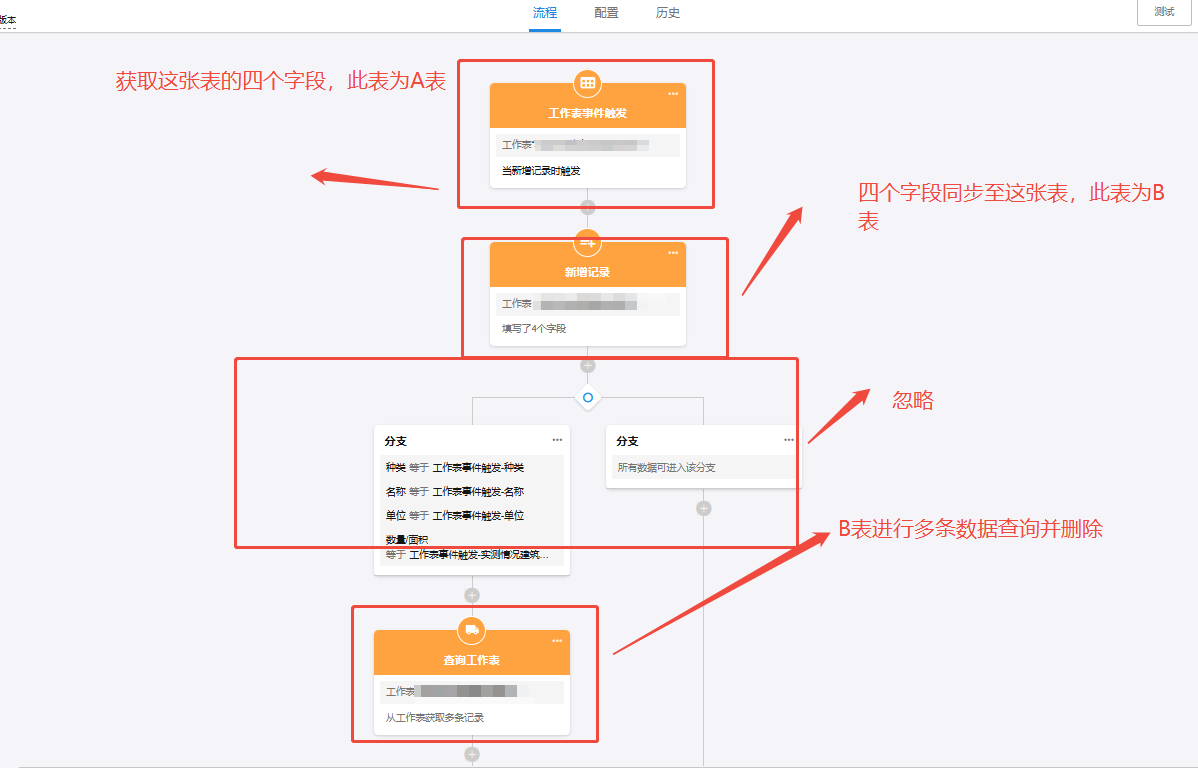
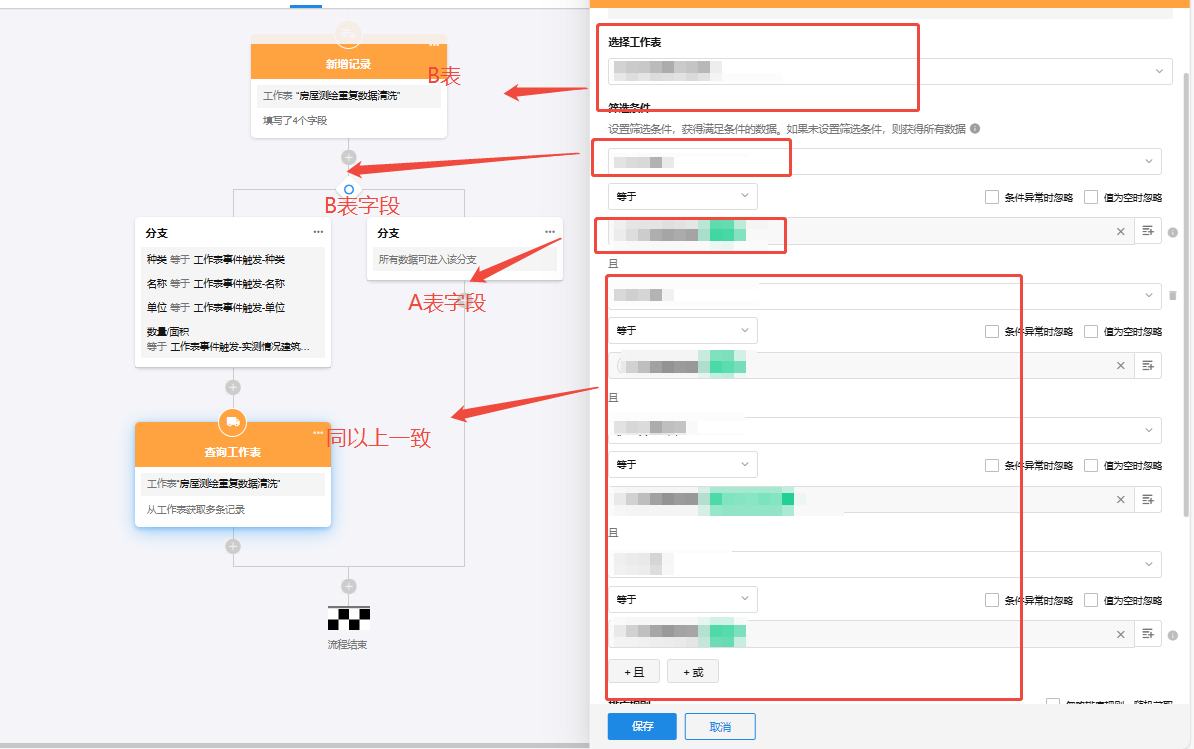 这种方式为什么无法实现?
这种方式为什么无法实现?

添加“Same Record Amount”字段,用工作流算好填进去,即可。

可以使用代码块进行数据清洗,然后工作流获取新增
可有较为具体的实现方案
可以使用代码块进行数据清洗,然后工作流获取新增