请问下面这种查询方式,索引怎么创建才正确,是按照 1、2 这种分开创建好,还是 3 这种组合创建好,感谢感谢!

请问下面这种查询方式,索引怎么创建才正确,是按照 1、2 这种分开创建好,还是 3 这种组合创建好,感谢感谢!
 有1人点赞
有1人点赞 
同问 +1
索引没优化好的话,数据量多了,慢查询动不动就把 CPU 资源占满了,这个真的很头痛
可能我们设置的索引没有起到效果
需要一种观测手段,比如利用 mtools 工具,可以对 MongoDB 的日志进行慢查询日志的分析,然后根据这个分析找到慢的语句,再进行索引的设置
另外,设置好索引后,也还需要使用 explain 来看下查询语句的执行计划,是否可以很好的利用索引

我有张 150w 的表 加了索引慢的很
我也是头痛得要死,数据一多,加了索引也慢得很

👍

我有张 150w 的表 加了索引慢的很
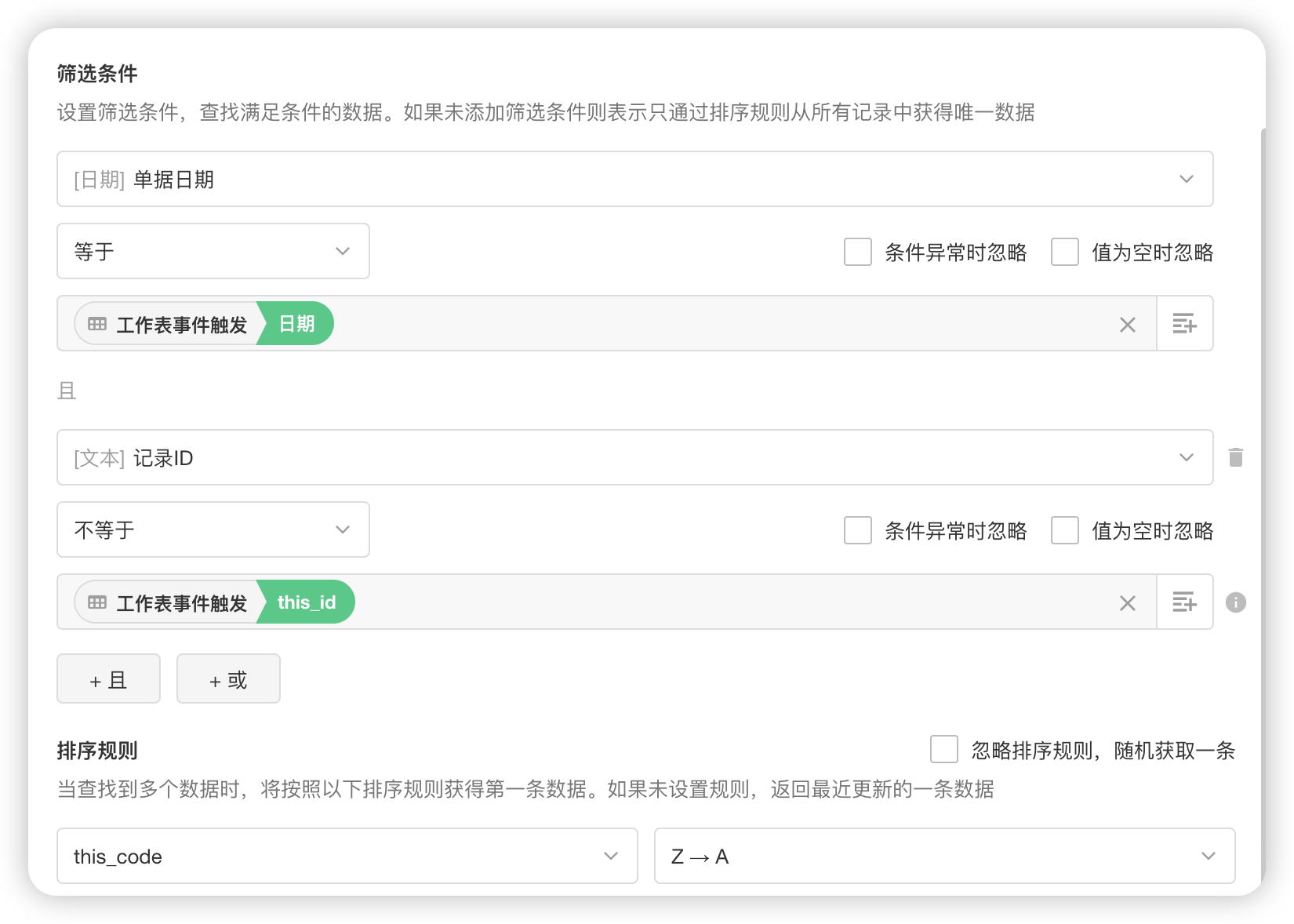
抱歉,之前回复的信息有误,也就是关于复合索引,需要遵循左前缀原则
即 查询条件必须从第一个字段开始匹配,然后是第二个字段,以此类推
下面是一个简单的例子,可以动手来验证
-- 创建集合并插入文档
db.users.insertOne({
"name": "Alice",
"age": 25,
"location": "New York"
})
-- 创建一个复合索引 name 和 age
db.users.createIndex({ name: 1, age: 1 })
-- 使用explain来验证,第二个查询语句的执行计划是 COLLSCAN,并没有利用到复合索引
db.users.find({ name: "Alice" }).explain("executionStats")
db.users.find({ age: 25 }).explain("executionStats")

你这个等值查询就能快速查出重复项了 👍。双手支持
再补充一下,一起讨论。
随着大家对 mingdao 云使用程度越来越深入,性能问题多半会成为一个热点问题:如何能够观测数据库的性能(特别是慢查询),如何能够利用相关工具或手段,对索引进行优化设置,等等。
等值 查询:可以很好地支持 S1 字段的等值查询。因为 S1 字段是索引的第一个字段,查询将直接使用索引进行快速定位。范围 查询:可以支持,但查询效率可能不如 等值查询那么高。升序 查询:可以支持 S1 字段的升序查询,但查询效率不如 S1 字段降序查询。降序 查询:可以非常好地支持 S1 字段的降序查询。因为索引已经按照"S1 降序 + S2 降序"的顺序建立,可以直接利用这个顺序进行高效的降序查询。等值 查询:可以利用这个索引高效 地执行对 S2 字段的等值查询。范围 查询:查询效率 可能不如S2字段的范围查询。因为,联合索引是按照 S1 先降序,然后 S2 再降序,这个时候,S2 的记录排序,可能不是严格的升序或降序,需要额外的排序步骤会增加查询的时间开销。升序 查询:查询效率 可能不会太高,同 S2 范围查询,需要进行额外的排序操作。降序 查询:查询效率 会略高于S2升序排序。+10086

同问 +1!!!