怎么用代码块将附件里的 pdf 或者 word 识别为文字并输出部分内容

求助
6 / 850
怎么用代码块将附件里的 pdf 或者 word 识别为文字并输出部分内容
集成的准确率太低了,而且高精度的还要花钱
好勒谢谢
看你的应用要实现的业务功能的复杂程度了,如果只是一些类似表格的增删改查场景,不涉及过多的数据处理,数据集成,那对业务比较熟悉,做好数据模型就可以了
如果涉及到数据处理、数据集成的场景,要么就是自己写程序来实现(代码块用好了,也是可以的),要么就是去找一些成熟的三方系统集成进来
去集成里面搜 百度云办公文档识别 用集成就可以了代码块解决不了,你的太复杂了
集成的准确率太低了,而且高精度的还要花钱
实现效果:
mingdao 的代码块支持 nodejs 和 python,你可以这样问下 gpt
下面是示例代码,vscode 下可以执行(需要安装 nodejs),调试后,可以将其适配到 mingdao 的代码块里,不过这个过程可能会遇到新的问题,如果你不是开发者,就不要研究了哈
const fs = require('fs'); const PDFParser = require('pdf-parse'); const { Document, Packer } = require('docx'); // 读取并解析PDF文档 async function parsePDF(filePath) { const dataBuffer = fs.readFileSync(filePath); const pdf = await PDFParser(dataBuffer); console.log(pdf.text); // 输出全部文本内容 } // 读取并解析Word文档 async function parseWord(filePath) { const dataBuffer = fs.readFileSync(filePath); const doc = new Document(dataBuffer); const text = doc.getBody().getText(); // 获取整个文档的文本内容 console.log(text); } // 调用函数解析文档,替换这里的地址 const pdfFilePath = 'path/to/your/word/document.pdf'; const wordFilePath = 'path/to/your/word/document.docx'; parsePDF(pdfFilePath); // parseWord(wordFilePath);
谢谢大佬,感觉用明道云很难啊
实现效果:
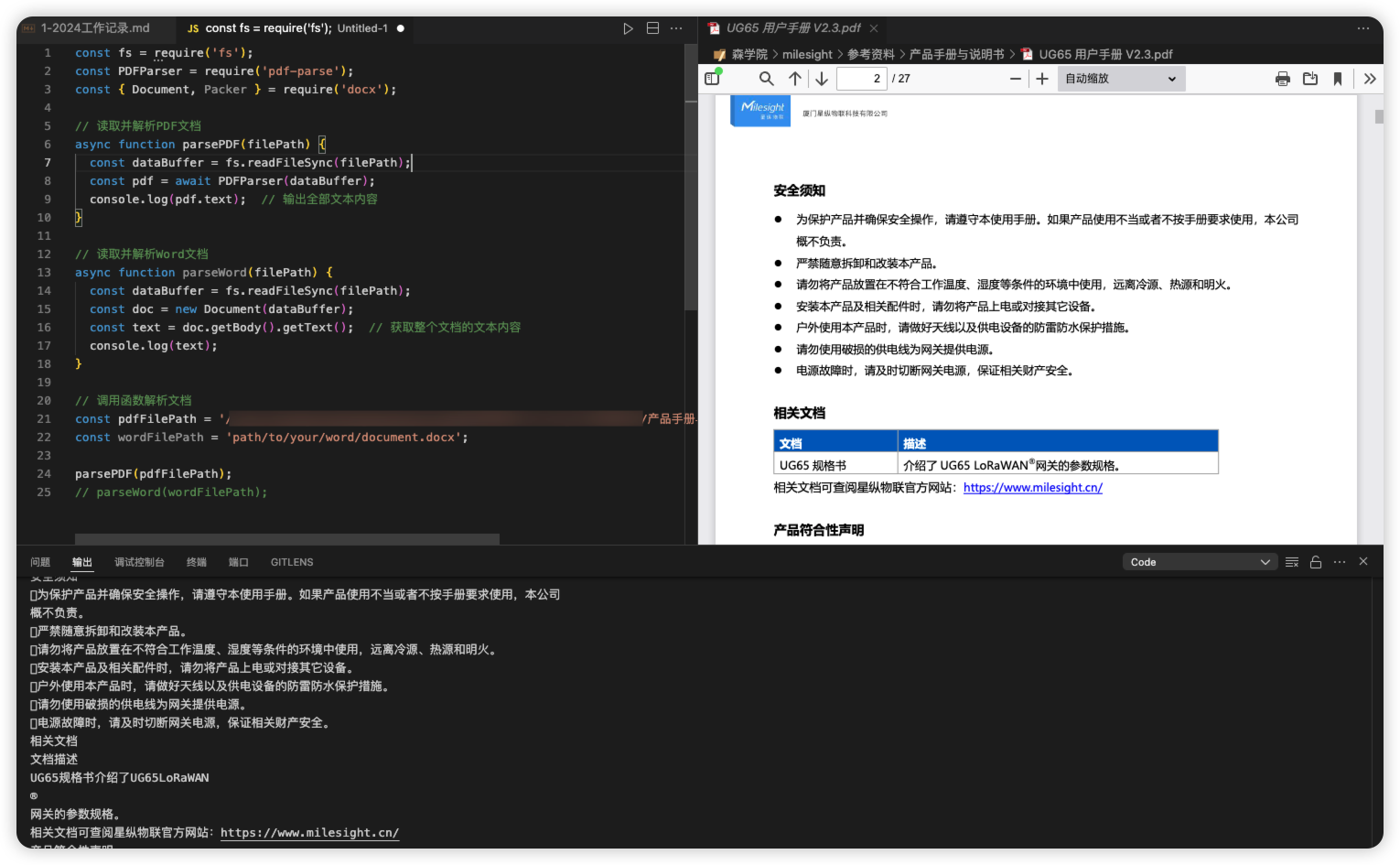
mingdao 的代码块支持 nodejs 和 python,你可以这样问下 gpt
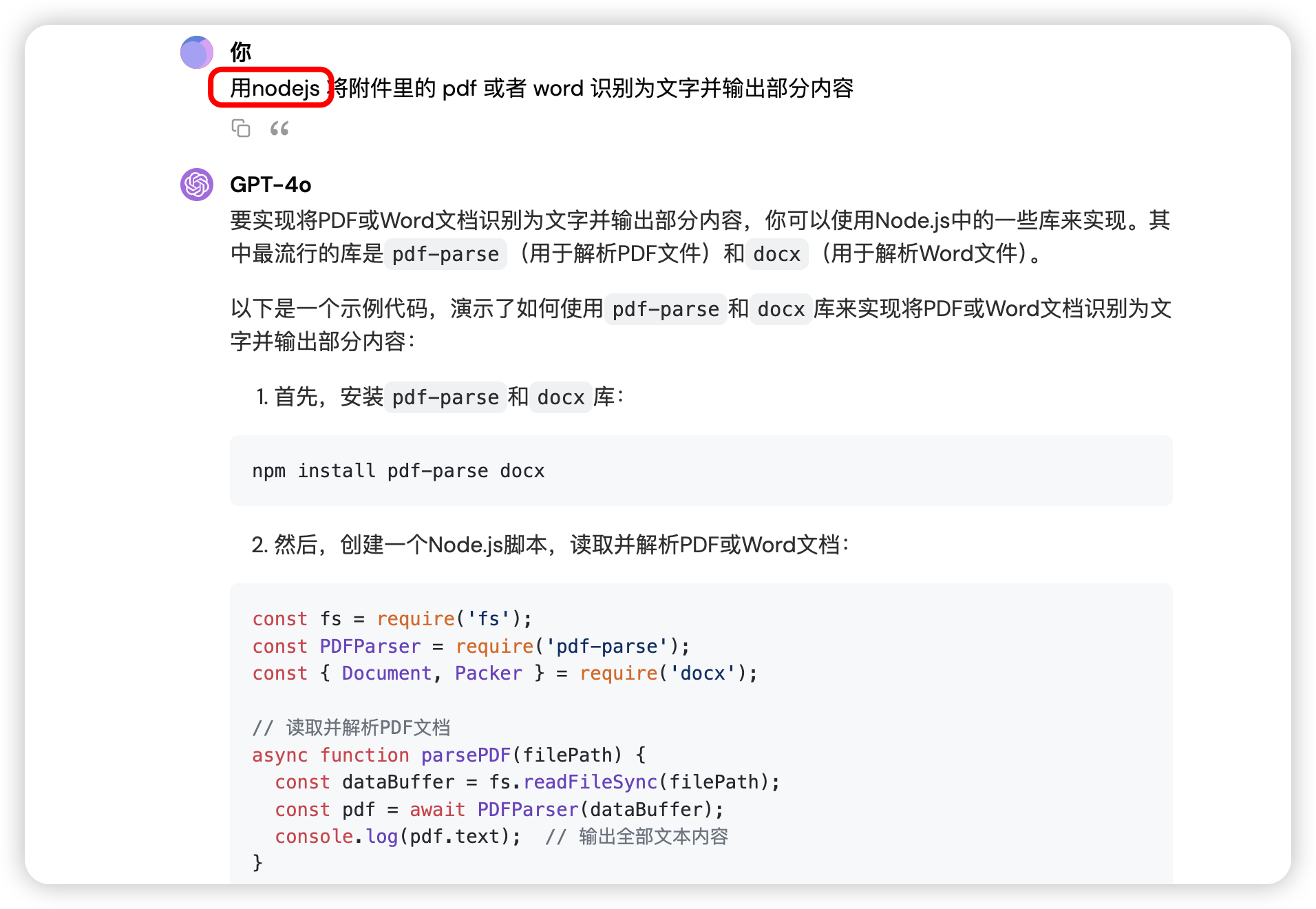
下面是示例代码,vscode 下可以执行(需要安装 nodejs),调试后,可以将其适配到 mingdao 的代码块里,不过这个过程可能会遇到新的问题,如果你不是开发者,就不要研究了哈
const fs = require('fs');
const PDFParser = require('pdf-parse');
const { Document, Packer } = require('docx');
// 读取并解析PDF文档
async function parsePDF(filePath) {
const dataBuffer = fs.readFileSync(filePath);
const pdf = await PDFParser(dataBuffer);
console.log(pdf.text); // 输出全部文本内容
}
// 读取并解析Word文档
async function parseWord(filePath) {
const dataBuffer = fs.readFileSync(filePath);
const doc = new Document(dataBuffer);
const text = doc.getBody().getText(); // 获取整个文档的文本内容
console.log(text);
}
// 调用函数解析文档,替换这里的地址
const pdfFilePath = 'path/to/your/word/document.pdf';
const wordFilePath = 'path/to/your/word/document.docx';
parsePDF(pdfFilePath);
// parseWord(wordFilePath);

去集成里面搜 百度云办公文档识别 用集成就可以了代码块解决不了,你的太复杂了