曾经实现的一个较为复杂的场景,该场景在一些 CRM 系统中比较常见,应该也有不少用户遇到过类似需求,今天简单分享下自己的思路,如有遇到类似场景的用户可以在评论区沟通。
先上需求:
以下是一张线索报备表单,用于管理分销商的线索报备,由于线索来源广,销售人员较多,所以很难避免线索重复的情况。因此用户想实现一个自动查重的逻辑,帮助报备人员及时识别重复风险。
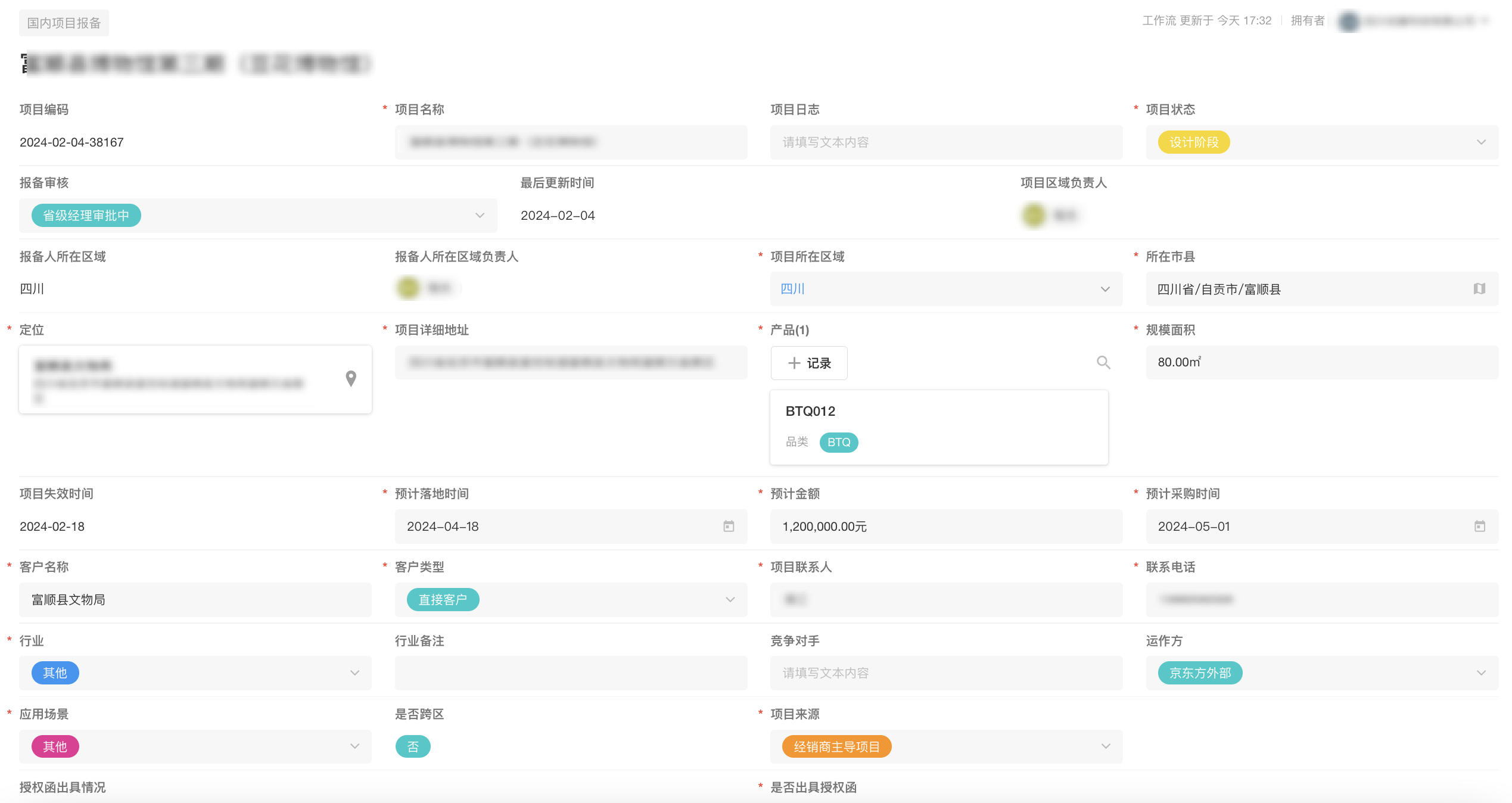
以下是查重规则:
1、判重范围:所有有效线索(报备审核字段状态不为项目无效)
2、判重方法:
① 新线索提交后,在有效线索中,筛选出交付地和新线索存在重复市的线索
② 计算新线索和有效线索中“最终客户名称”、“项目名称”、“项目详细地址”的重复率。在新、旧两条线索的字段中,选择连续重复字段。统计重复字段长度,并计算其和新线索、旧线索的重复率,取最大值为字段的重复率,记为 N1、N2、N3;
③ 计算最终重复率 N=N1a+N2b+N3c [a+b+c=1;a=20;b=60;c=20]*
如果 N1、N2、N3 任意一数值大于 0.75(S1),判定两条线索重复;如果 N>0.7(S2),判定两条线索重复。
实现方案如下:
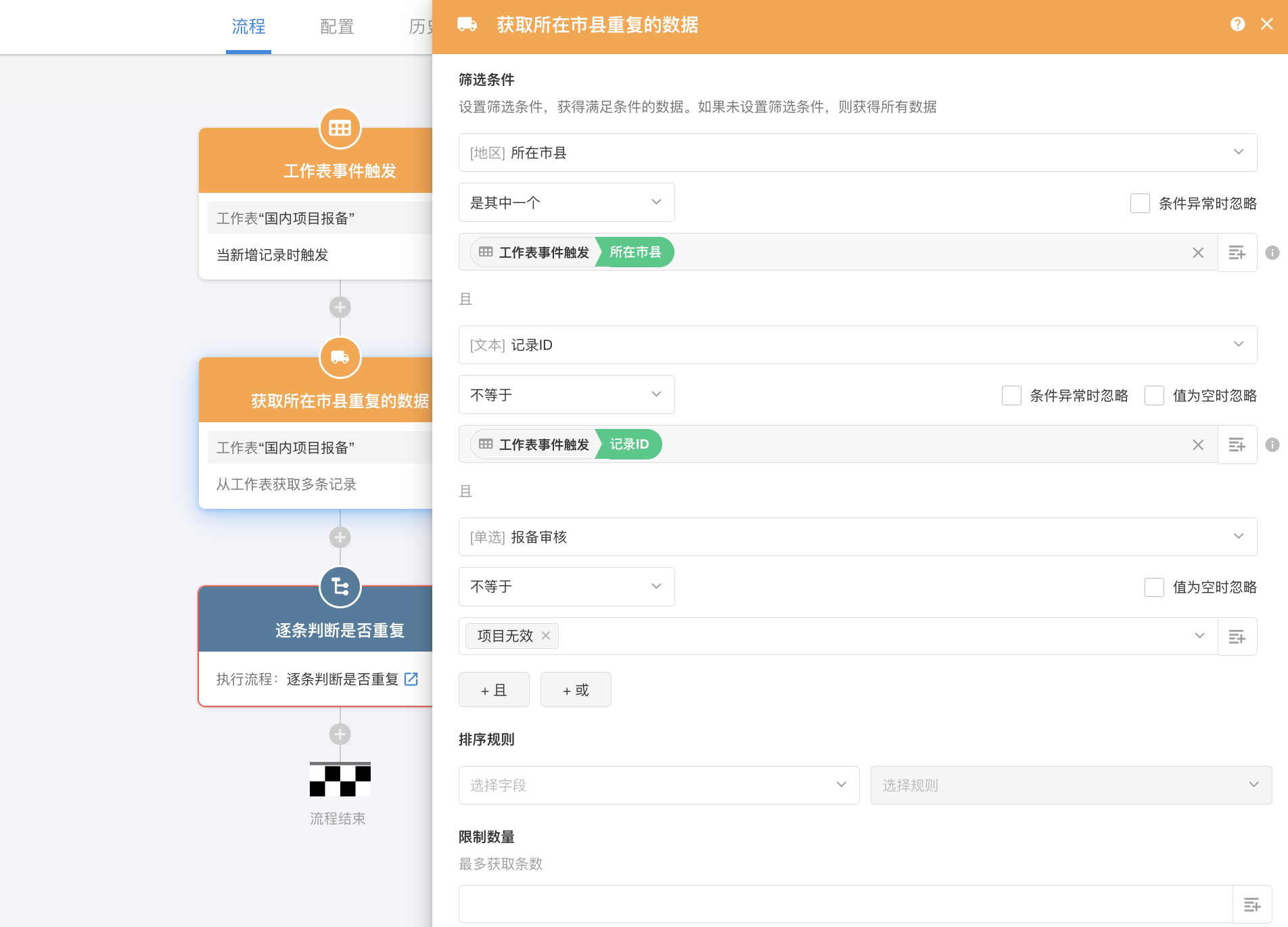
查重限制了范围:1、仅查重有效线索;2、查重范围控制在市县级;因此,在流程开始前,我们将查重获取的数据范围先进行缩小。这里有一点要注意,很多同学在做控制范围这一步,往往会遗漏掉当前触发数据,导致最终结果不准确,所以,这里我们加一个一项筛选条件,通过记录 ID 排除当前触发数据。
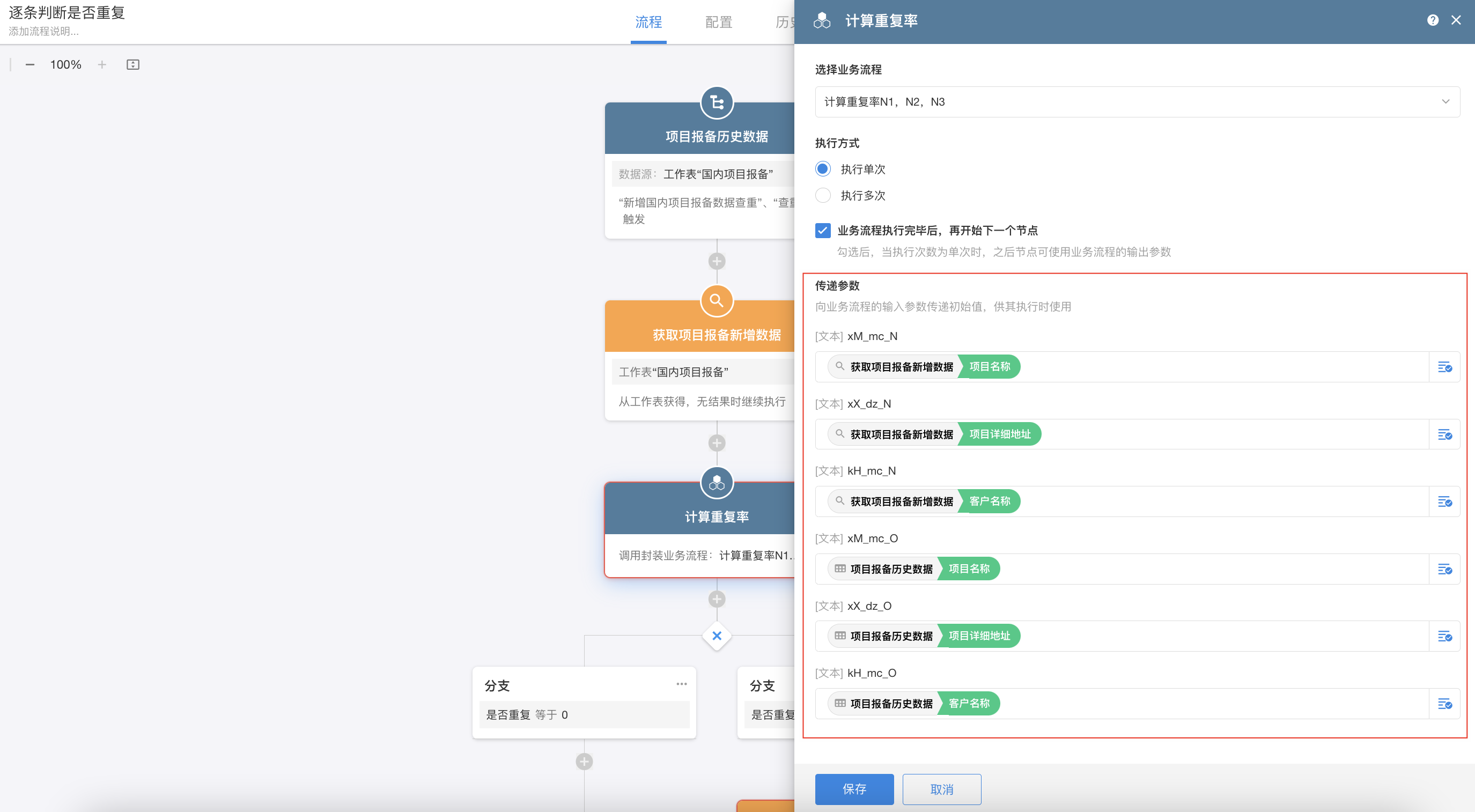
接下来,进入到子流程,按照给出的规则,我们首先要计算 N1、N2、N3。规则比较复杂,单独写到了一个封装业务流程中,也便于修改和重复调用。执行重复率计算之前,要将所需参数进行传递。这里分别按照需求中提到的三个字段,传递了新增记录及满足筛选条件的历史记录。
按照规则,我们分别要对两组字段进行长度统计和重复率计算,得出 N1、N2、N3 的值。
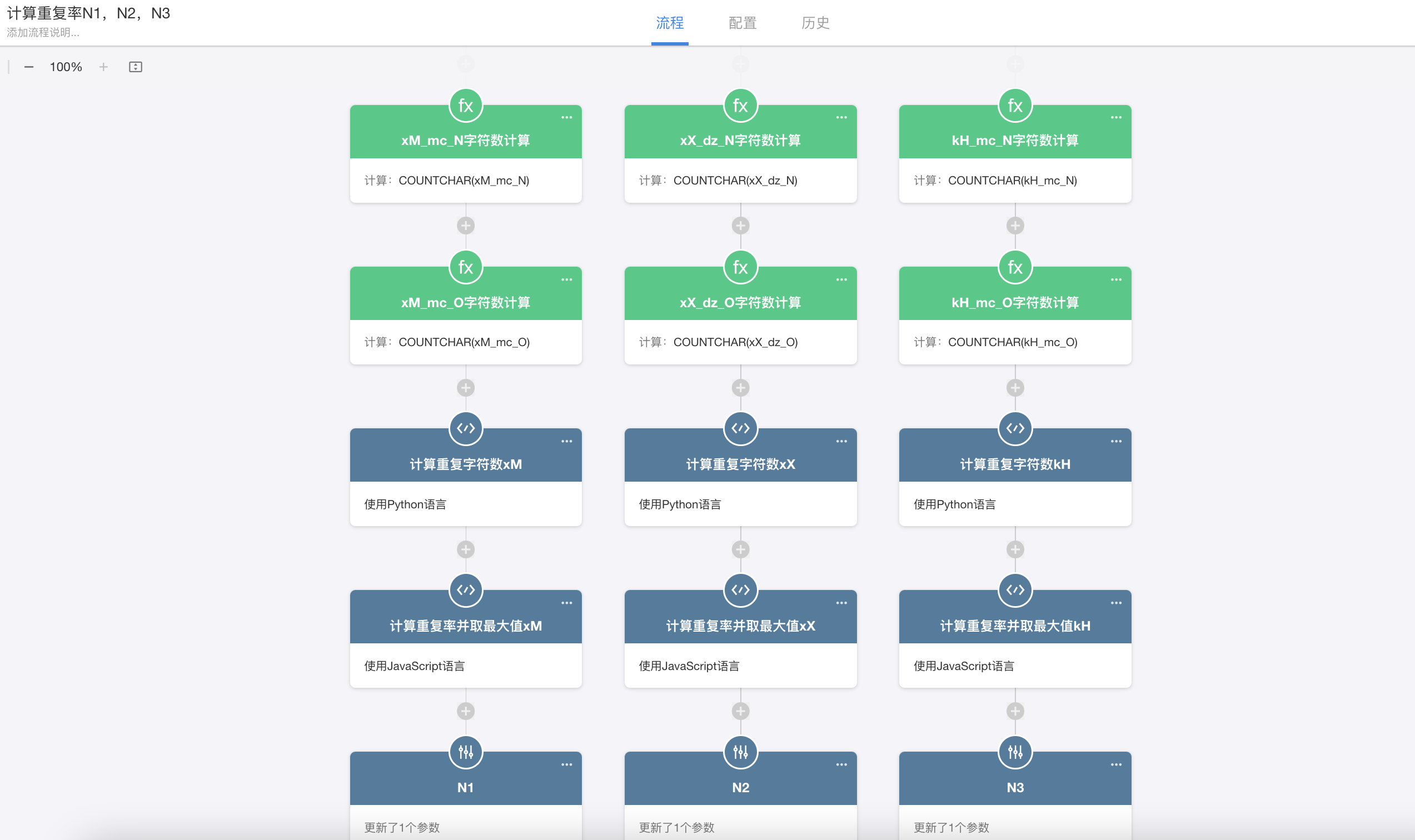
这里统计字符数利用明道搭载的函数实现。
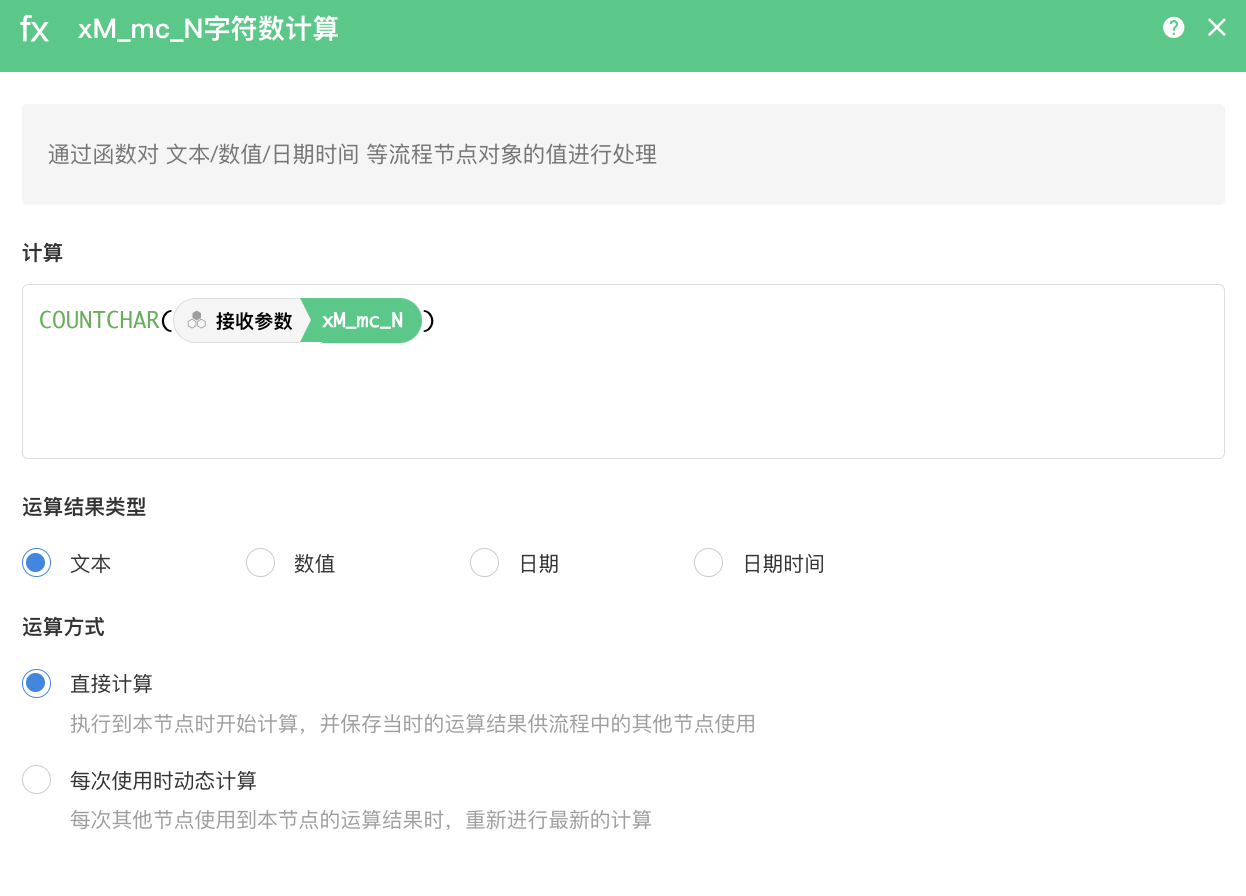
通过代码块对两个字段之间进行比较,得出重复字符数。
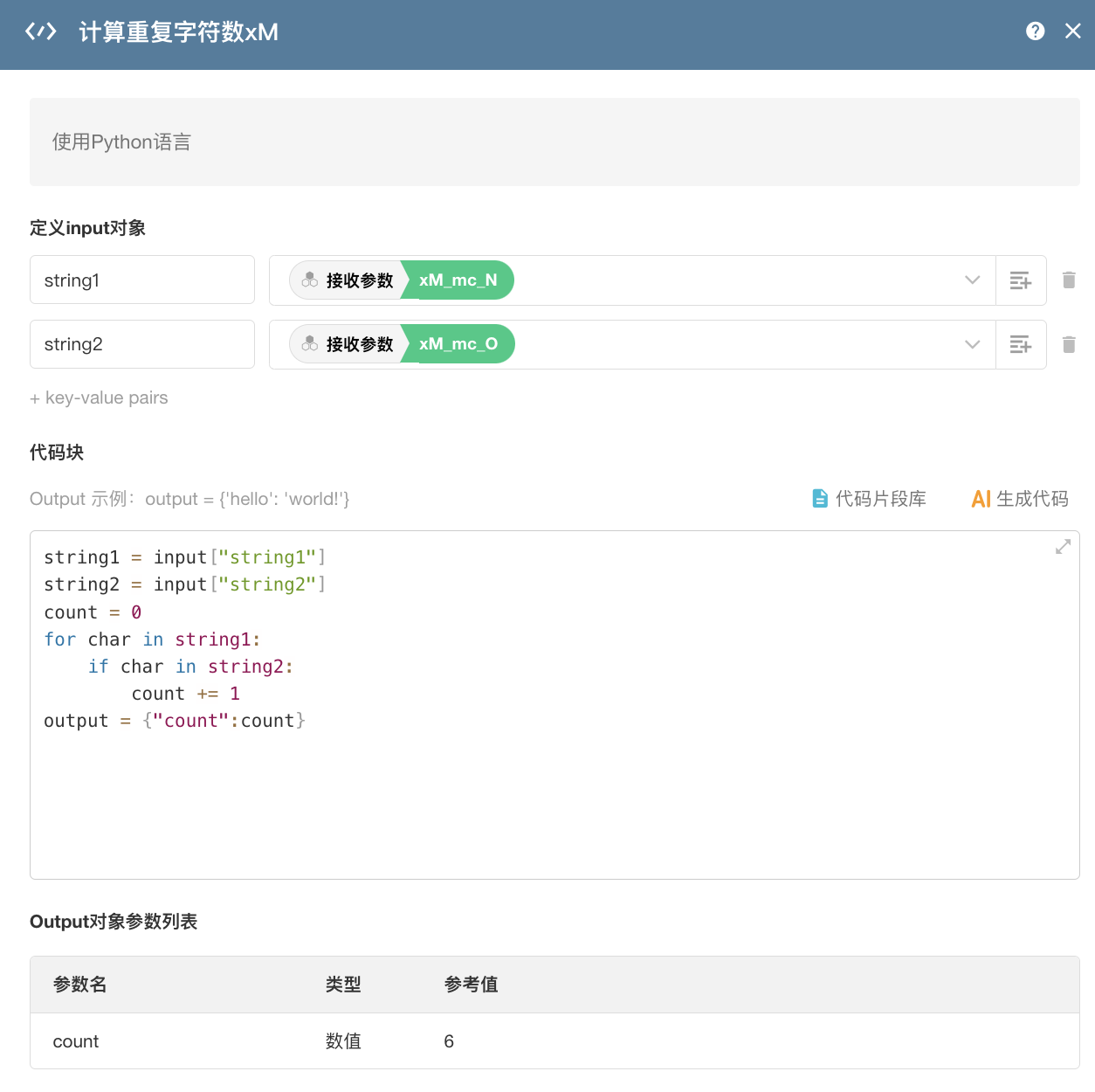
拿到重复字符数后,通过代码块计算,得出重复率,计为 N1。N2、N3 的计算逻辑同理。
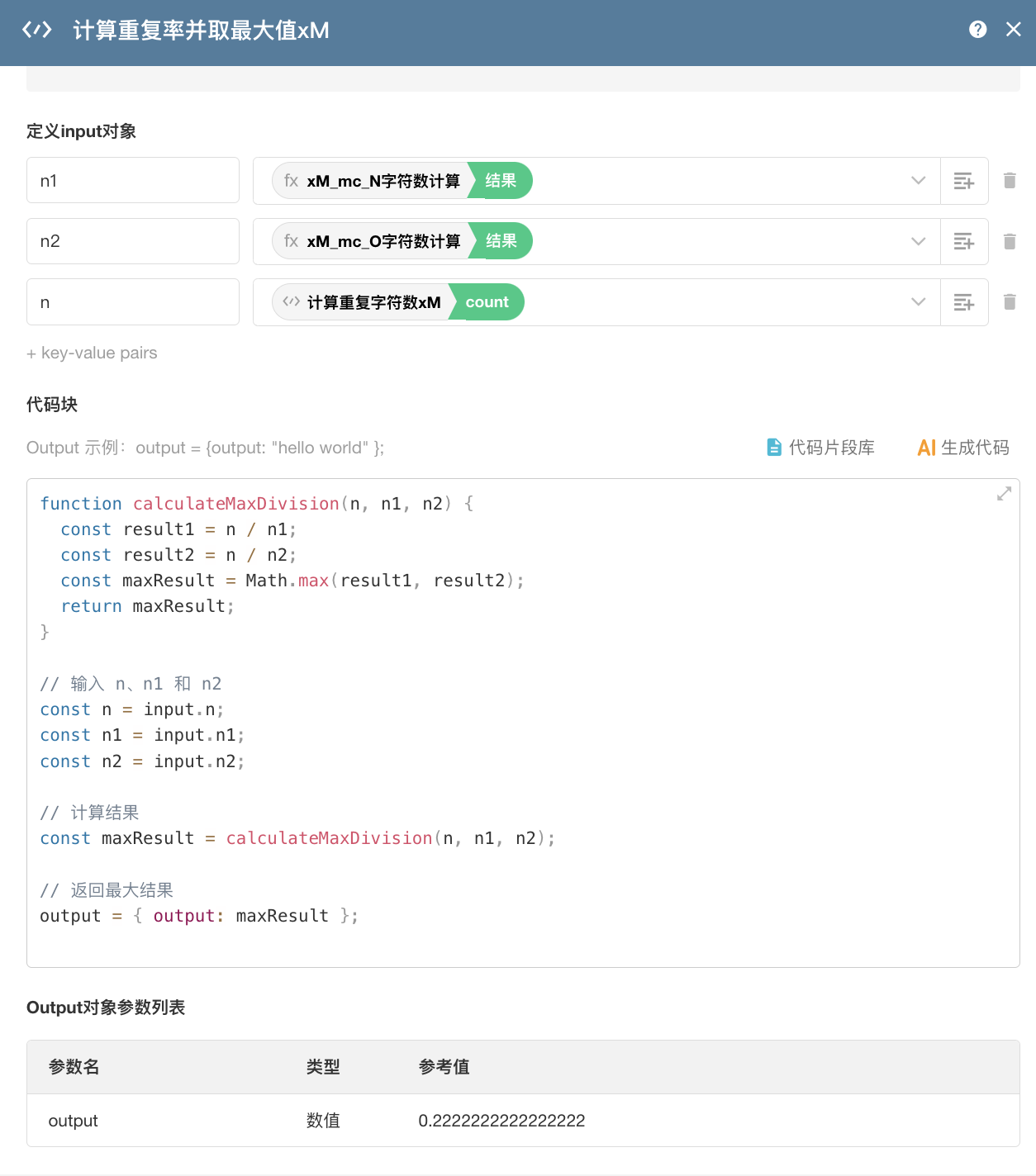
拿到计算所需的系数之后,接下来就需要通过规则中给到的公式,进行组装。这里为了后期调整系数方便,做一个表单单独存放系数。(因为是之前做的,现在完全可以用全局变量存放)

首先,判断 N1、N2、N3 中任意一个数,是否大于 S1
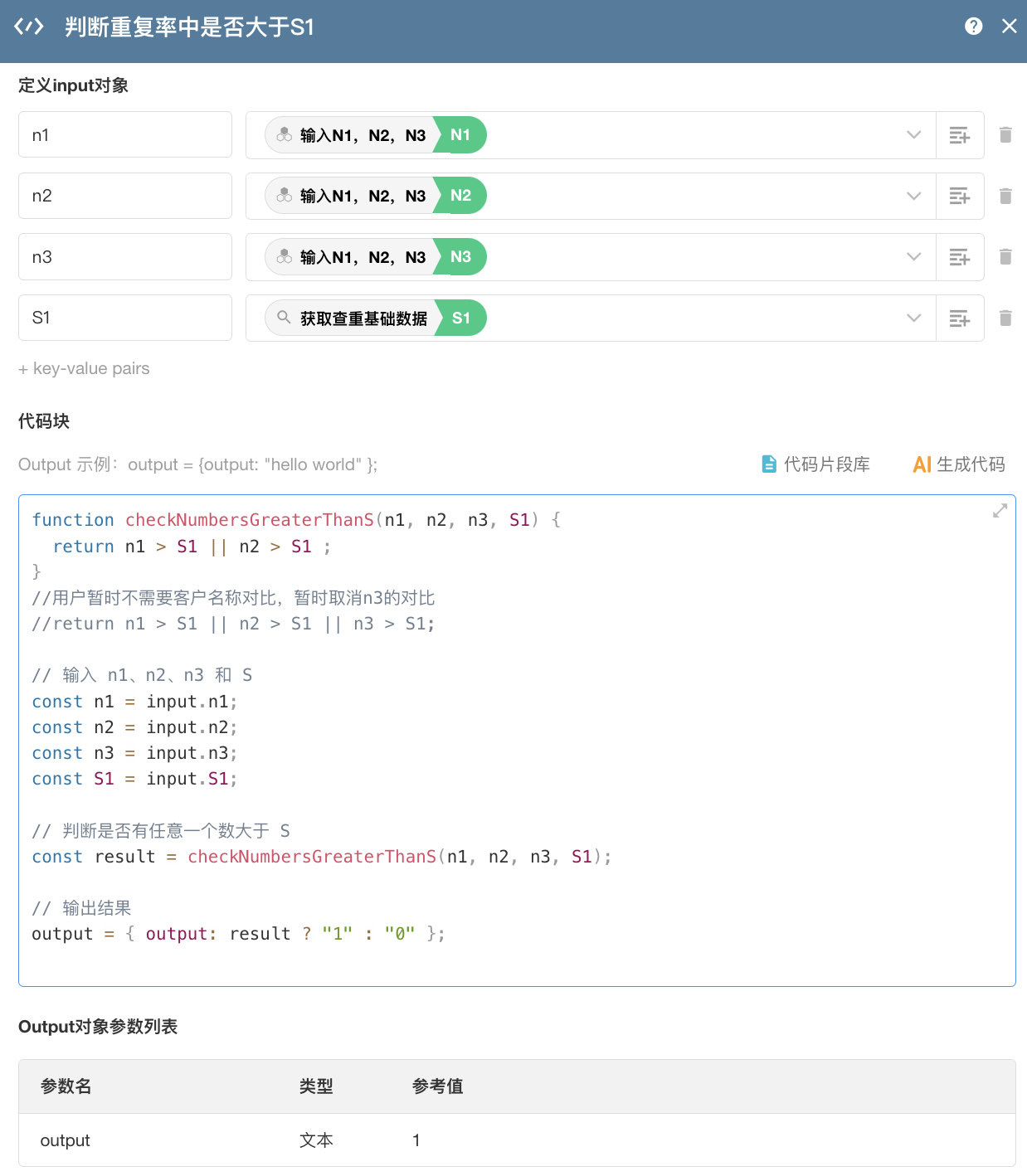
然后判断 N 是否大于 S2
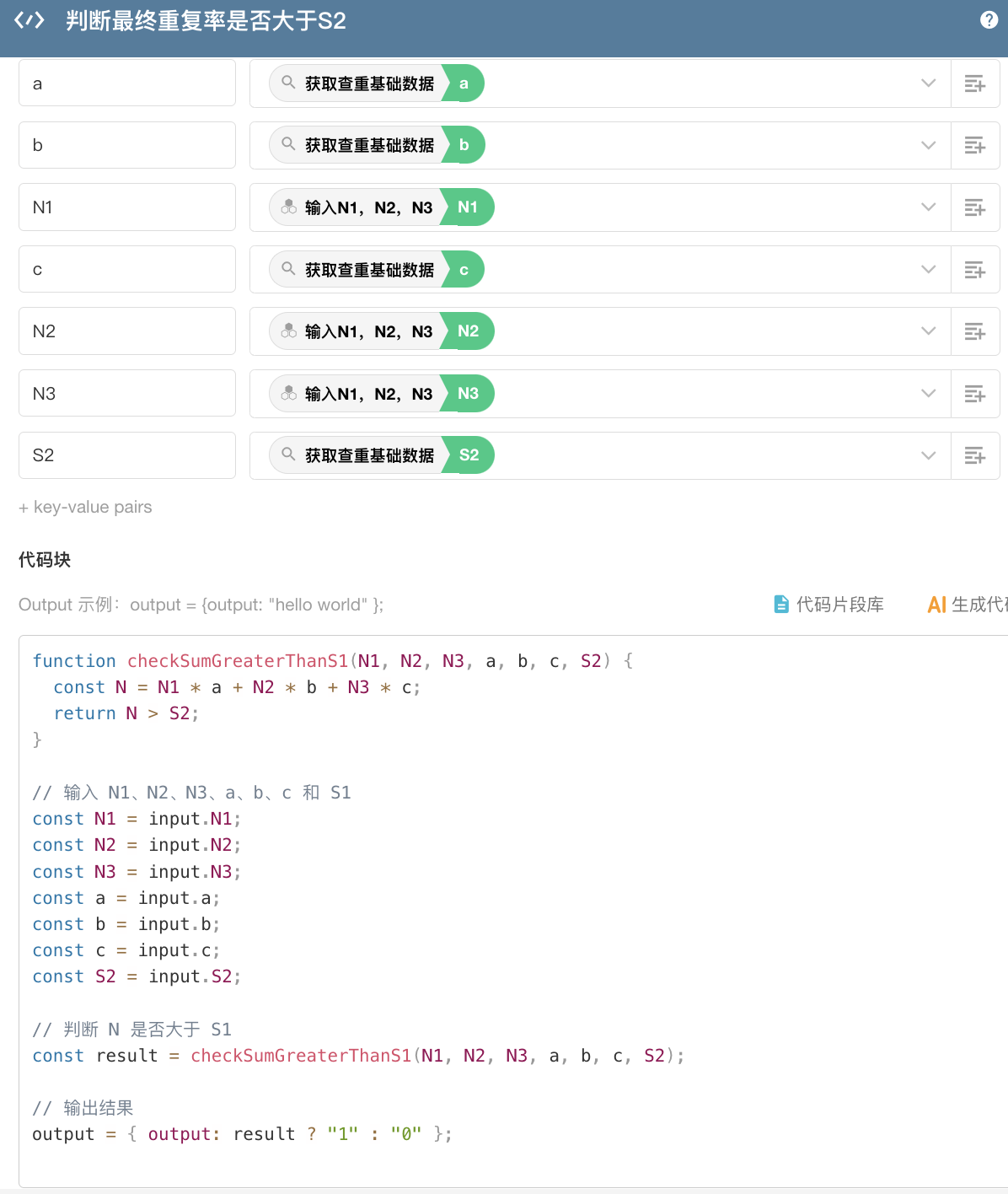
最终两个代码块的结果,输出给调用流程,即可判断出,历史的线索与当前线索是否存在高度重合。




