0. 前言
今天遇到一个项目上工作流消费慢的问题,给了他们一些建议,其中一项是关于 MongoDB 索引优化,故翻出之前的笔记发表在这里。
1. MongoDB 索引原理
关于 MongoDB 索引的原理,详见MongoDB 索引原理,概括来说:
- 优化前,是全表扫描
- 通过额外存储一份索引数据(索引通常采用 btree 的结构化存储),使查询数据的时间复杂度降低为 O(logN)
通过空间换时间的思想,加上索引数据结构的设计,降低了算法复杂度,从而提升了查询效率
2. 索引优化实践
2.1. 首先,你需要通过一个方式来查看当前数据库的性能表现
本案例是通过 mongotop 命令来观测的,当然,你也可以通过开启慢日志,亦或是进行查询计划(即 explain)来进行分析。
- mongotop 命令非常简单,如下图所示,
mongogotop 10意思是每 10 秒输出一次报告,更为详细的使用方法见官网 mongotop 介绍
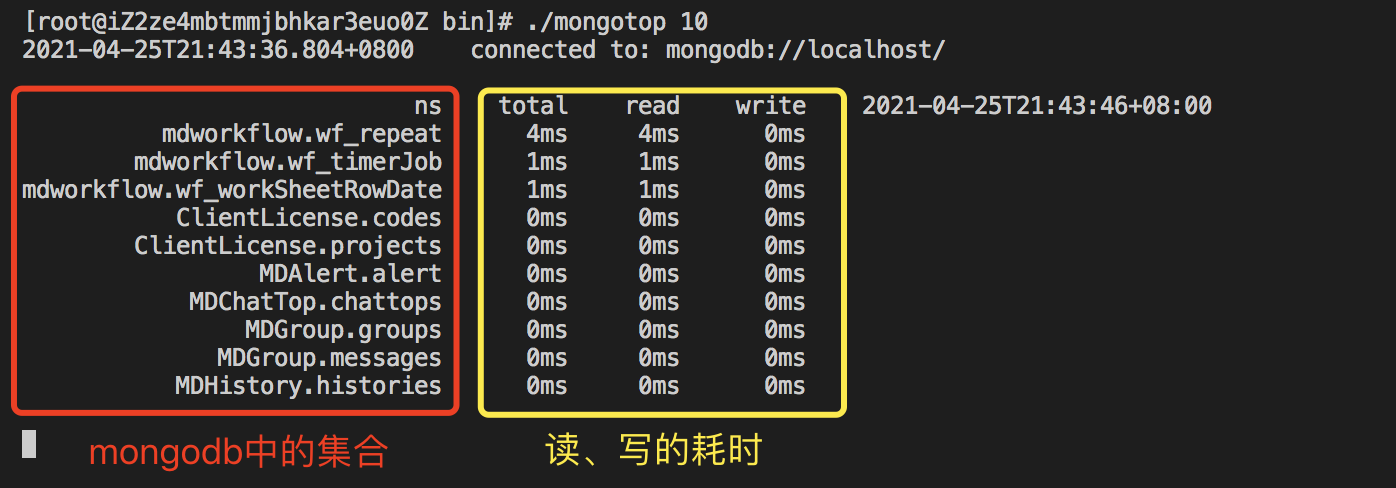
- 我们先来看下优化前的性能表现,下面是模拟了一个批次的请求,里面有 100 条数据,每条数据都会根据设施名称这个字段进行数据库的查询,以识别该条数据是新增操作,还是更新操作:
- 可以看到在 40 秒左右的观测时间里
mdwsrows.ws602c7c7ae86050796cc5b35c这个集合的读性能表现在 9 千毫秒上下
- 可以看到在 40 秒左右的观测时间里
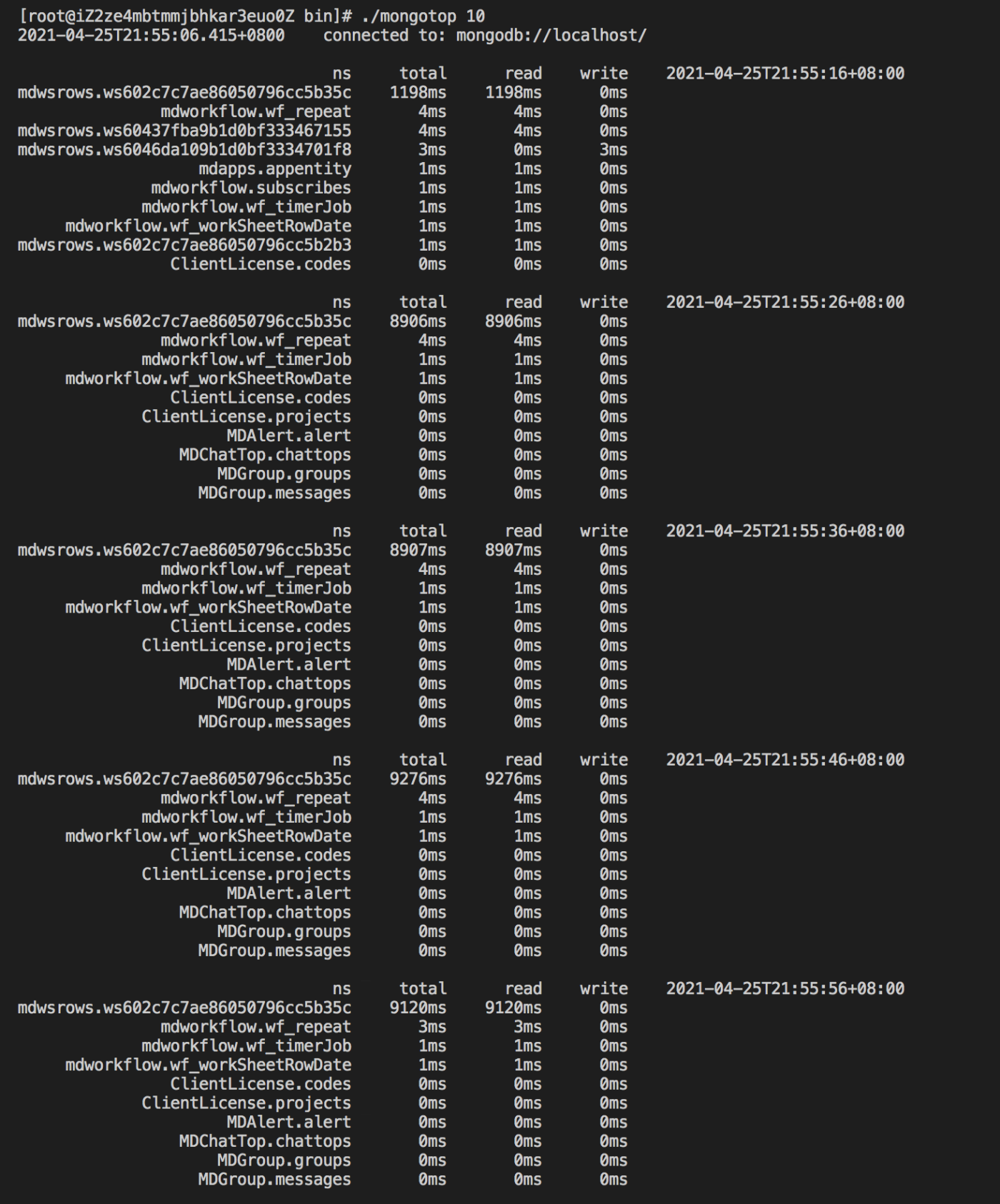
2.2. 接下来,我们给设施名称字段添加索引,然后再进行观察
- 查看当前索引设置,系统内置了 3 个索引,但与我们要使用的业务字段无关,因此我们需要进行添加
## 进入容器
docker exec -it $(docker ps | grep tarsier-community | awk '{print $1}') /bin/bash
## 连接mongodb
/init/mongodb/mongo
## 查看数据库
show dbs;
## 切换数据库到mdwsrows,该库存储了我们需要查找的记录
use mdwsrows;
## 查看库下有哪些集合
show tables;
## 查看mdwsrows.ws602c7c7ae86050796cc5b35c索引设置,存在3个默认的索引
db.ws602c7c7ae86050796cc5b35c.getIndexes();
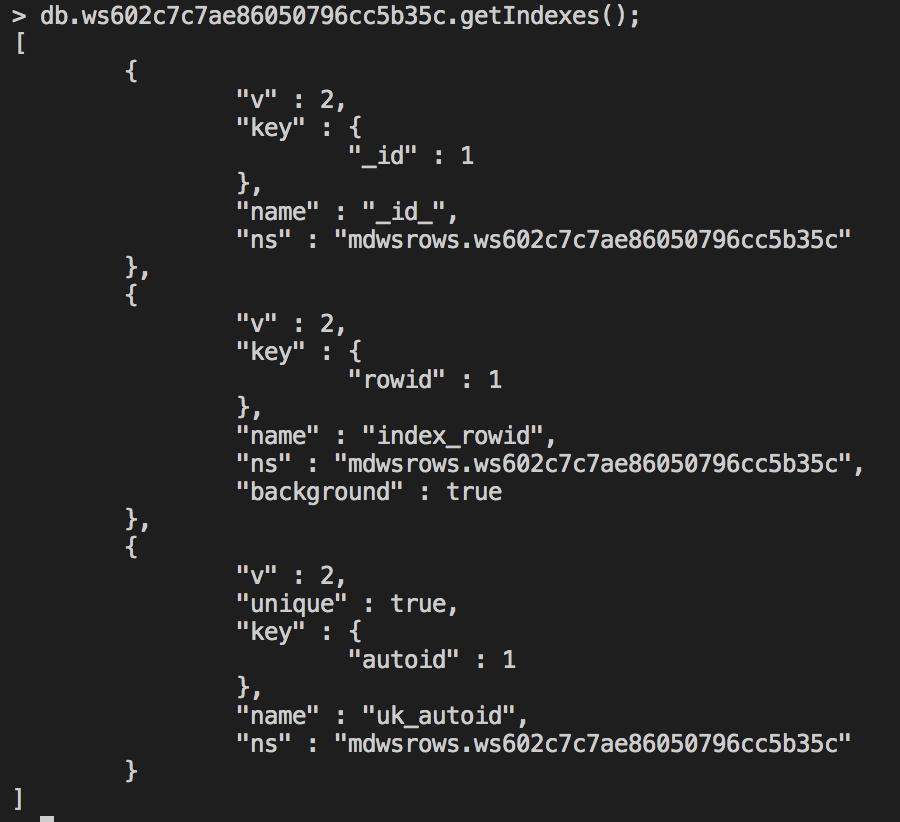
- 添加索引,MongoDB 提供了两种建索引的方法
- 前台方式(缺省情况):这个操作将阻塞其他的所有操作(也就是会占用一个写锁),即该集合上的无法正常读写,直到索引创建完毕,如果集合的数据量很大,建索引通常要花比较长时间,特别容易引起问题
- 后台方式(background 为 1):不需要长时间占用写锁,适合为超大表建立索引
## 通过后台的方式建立索引,background为1
## 602c7c7ae86050796cc5b2eb,是添加索引的字段,即设施名称
db.ws602c7c7ae86050796cc5b35c.createIndex({"602c7c7ae86050796cc5b2eb":1},{"background":1});
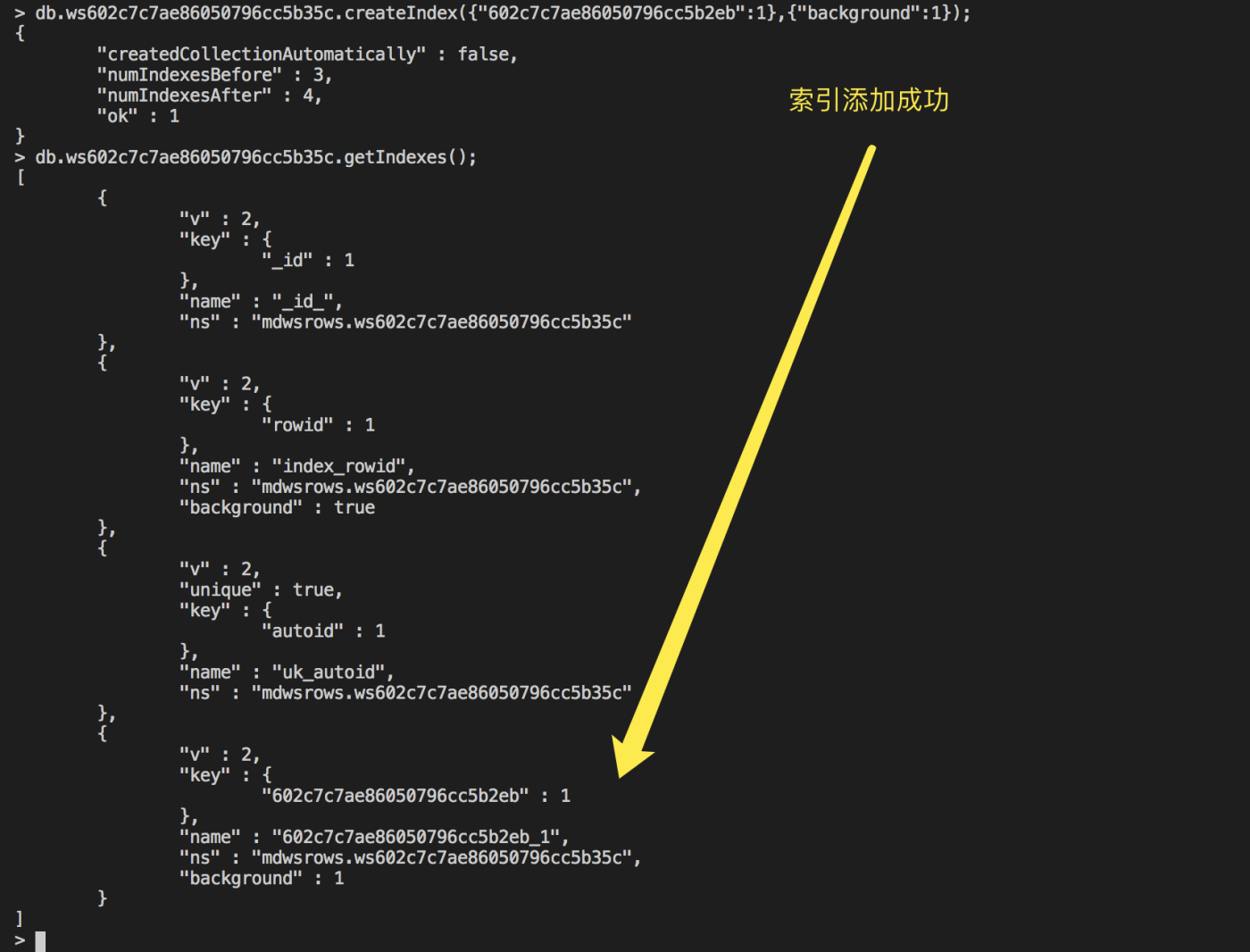
- 数据库中字段的标识与业务字段的映射关系,可以通过 API 说明去进行查询
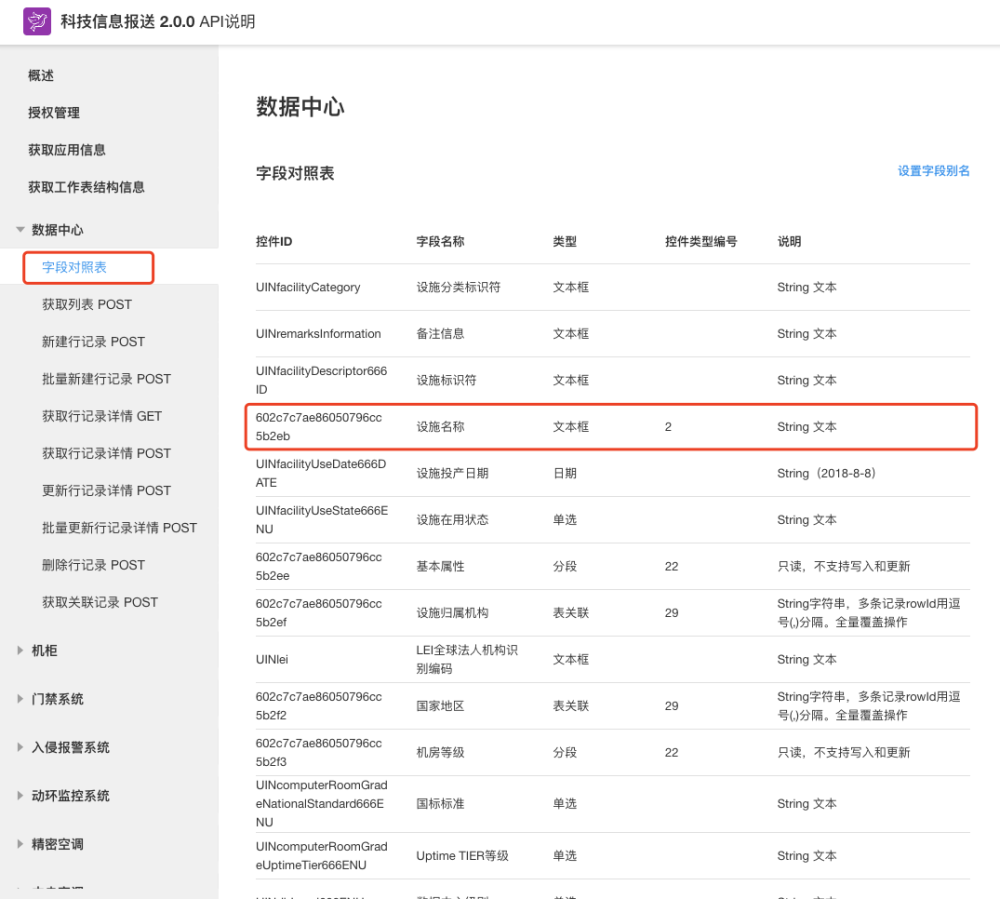
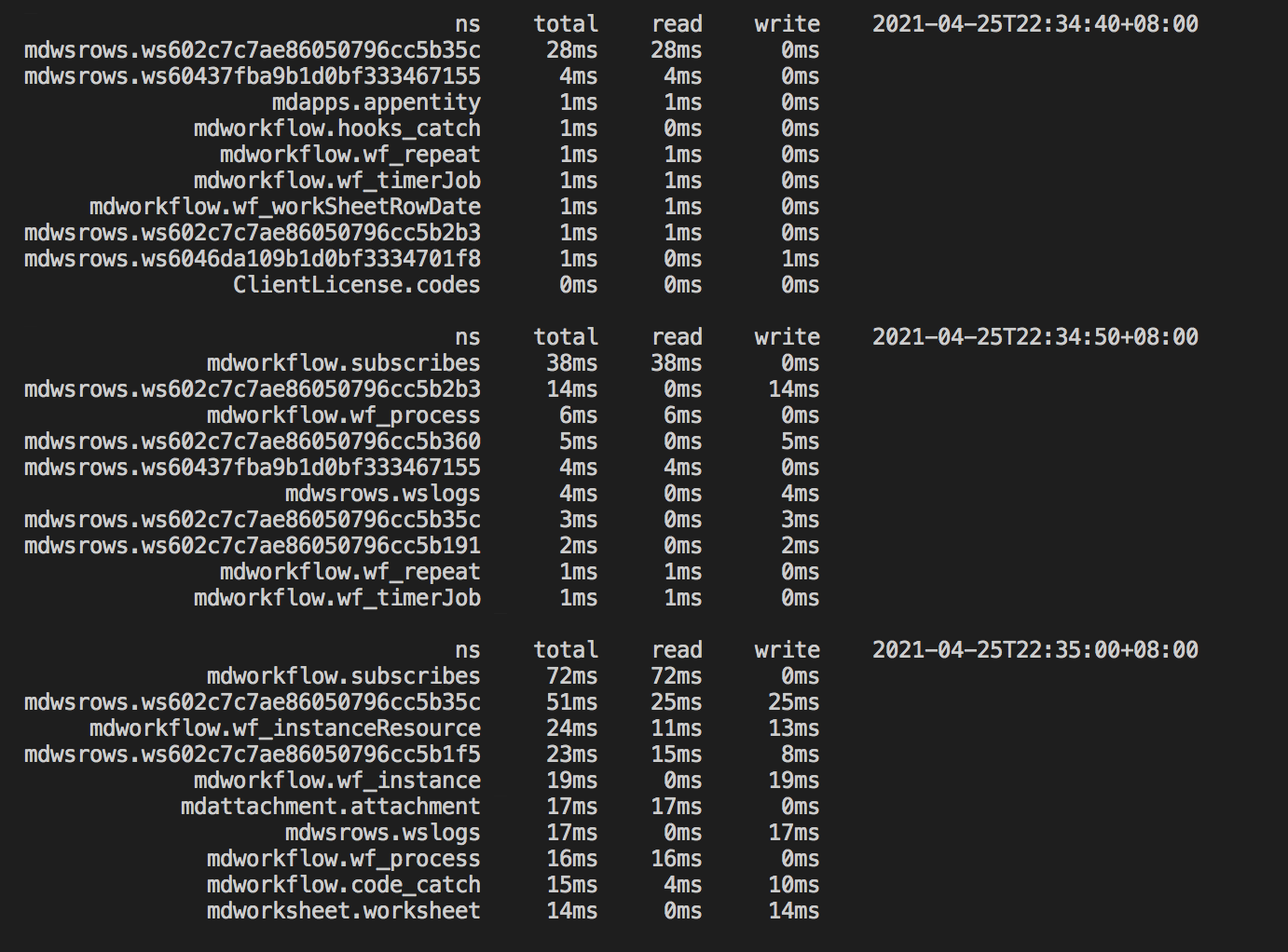
2.3. 最后,我们来验证下索引优化的效果
再次模拟了一个批次的请求,同样是 100 条数据的查询操作,可以看到在不到 20 秒的时间里,已经完成了查询和入库操作,读性能表已经下降到 100 毫秒以内
3. 写在最后
目前,mingdao 已经支持在页面上设置索引,极大的方便了系统的运行维护操作。
下面是一些相关概念的介绍,希望对你有所帮助。
3.1. 排序索引
- 在 MongoDB 中,如果对人员姓名字段创建了
排序索引(也称为 B-Tree 索引),那么在进行精确匹配查询时,这个索引确实可以加速查询过程;排序索引不仅可以加快排序操作,而且可以提高匹配特定值的查询效率,因为它允许数据库引擎快速定位到索引中的相应位置,并直接检索匹配的文档 - 例如,如果你有一个包含数百万条记录的集合,并且经常需要根据人员姓名进行精确查找,那么为人员姓名字段创建索引将极大地减少查询操作需要扫描的文档数量,从而显著提高查询性能
- 创建索引的 MongoDB 命令类似于:
db.collection.createIndex({ "personName": 1 })
- 这里的
1表示索引是升序的;对于精确匹配查询,索引的排序方向(升序或降序)并不重要,因为目标是快速找到具有特定姓名的文档 - 总结来说,对于精确匹配查询,创建适当的索引(在这个例子中是排序索引)确实可以显著提高查询速度
3.2. 唯一索引
- 在 MongoDB 中,
唯一索引和排序索引(B-Tree 索引)都可以加速精确匹配查询;唯一索引保证了索引字段的值在集合中是唯一的,而排序索引则没有这个限制;两者在查询性能上通常是相似的,因为它们都是基于 B-Tree 数据结构实现的,允许数据库高效地查找特定值 - 创建唯一索引的 MongoDB 命令类似于:
db.collection.createIndex({ "personName": 1 }, { unique: true })
- 这里设置
unique: true表示字段 personName 在集合中每个文档的值必须是唯一的 - 在性能方面,如果你仅仅进行精确匹配查询,
两种索引类型提供的性能是类似的,因为它们都利用了 B-Tree 的高效查找特性;然而,如果你还需要执行排序操作,那么排序索引会更加合适;如果你需要确保字段值的唯一性,那么唯一索引是必须的
3.3. 文本索引
- 在 MongoDB 中,文本索引(text index)是
专门为了支持对文本内容的搜索而设计的,它与排序索引(B-Tree 索引)和唯一索引在用途和工作原理上有显著不同。 - 文本索引允许你对文档中的字符串内容进行全文搜索,这涉及到对文本数据进行分词(tokenization)、过滤(如停用词的移除)和可选的词干处理(stemming);
文本索引主要用于实现搜索引擎式的查询,例如,搜索含有某些关键词的文档 - 创建文本索引的 MongoDB 命令类似于:
db.collection.createIndex({ "personName": "text" })
3.4. 多个索引时,前后顺序是否有差别
MongoDB 数据库,表 A 有两个索引,s1 和 s2,都是排序索引,查询条件 s1 s2,和查询条件 s2 s1,两者会有差别么
-
如果你为集合 A 创建了一个
复合索引- 其中索引的
字段顺序是(s1, s2),那么第一个查询(s1 然后 s2)将能够更有效地利用这个索引;这是因为MongoDB 的复合索引遵循前缀原则,即查询条件需要按照索引中字段的顺序来使用索引 - 相反,如果查询条件是 s2 然后 s1,而你只有一个(s1, s2)的复合索引,那么这个查询将不能高效地利用这个复合索引,因为 s2 不是索引的前缀
- 其中索引的
-
如果你有
两个单独的索引,一个是 s1 上的索引,另一个是 s2 上的索引,MongoDB 查询优化器会尝试选择最佳的索引来执行查询- 在这种情况下,
查询条件的顺序对于索引选择可能不那么重要,因为查询优化器会评估两个索引并选择一个看起来最有效的索引 - 不过,如果查询条件中的两个字段
都有高选择性,那么一个复合索引(s1, s2)或(s2, s1)通常会比单独的索引表现得更好
- 在这种情况下,
-
下面是创建复合索引的基本语法:
db.collection.createIndex({ "field1": 1, "field2": 1, ... })
- 记住,
复合索引中字段的顺序是很重要的,它决定了索引可以支持哪些类型的查询;MongoDB 中的索引遵循前缀原则,这意味着查询必须使用索引的最左边的字段作为其条件的一部分,才能有效地利用索引
3.5. 小结
- 查询类型
文本索引主要用于全文搜索,支持对词语的模糊匹配和相关性评分排序索引和唯一索引主要用于精确匹配和范围查询,以及支持字段的排序操作
- 性能
文本索引对于全文搜索优化得更好- 但对于精确匹配和排序查询,
排序索引和唯一索引的性能更佳;排序索引和唯一索引利用 B-Tree 结构,可以快速进行精确匹配查找和范围查找
- 用途
- 如果你需要搜索含有某些关键词的文档,那么
文本索引是必须的 - 如果你需要快速检索具有特定值的文档,或者需要对结果进行排序,那么
排序索引或唯一索引更适合
- 如果你需要搜索含有某些关键词的文档,那么
- 唯一性约束
唯一索引可以强制字段值的唯一性- 而
文本索引和普通的排序索引则没有这种约束








